在 RCNN 初步试水取得成功后,研究人员又迅速跟进,针对 RCNN 中的几点不足提出改进,接连推出了 fast-rcnn 和 faster-rcnn。关于这两篇论文,网上相关的文章实在是多如牛毛,因此,本篇博文不打算深入讲解,只是不落俗套地介绍一下它们改进的痛点,基本流程,以及我自己对一些小问题的理解。
RCNN 的问题
我们先回忆一下 RCNN 做了哪些事情:
- Selective Search 选出候选区域(region proposal);
- CNN 对这些区域提取特征;
- SVM 对 CNN 提取的特征进行分类预测;
- 一个简单的线性回归模型做 bounding box regression(就是对候选区域进行微调)。
原作者之一 rgb 在 Fast RCNN 的论文中就提出了 RCNN 几个很明显的短板。首先,训练是分阶段进行的。为了训练 RCNN,我们需要对 CNN 进行训练,然后,在用它提取的特征对 SVM 进行训练,完了还要训练一个线性回归模型,实在烦琐至极。其次,训练过程很耗费时间和磁盘空间。因为 CNN 是在 Selective Search 挑选出来的候选区域上进行的特征提取,而这些区域很多都是重叠的,换句话说,很多卷积运算都是重复的,另外,CNN 提取的特征需要先保存下来,以便后续对 SVM 的训练,而这些高维度的特征,占据的空间都是几百 G 大小。第三,检测过程很缓慢。这一点和第二点很类似,基本是由卷积运算的重复进行造成的。
Fast RCNN的改进
基本思路
针对 RCNN 这几个短板,很容易想到的一个改进就是对 CNN 卷积操作的结果进行重复利用,也就是说,我们可以先用 CNN 对整幅图片提取特征,得到某一层的特征图(一般是取全联接层前面的那一层),然后,用 Selective Search 对原图提取候选框,根据相应的缩放比例,可以在特征图上找出候选框对应的区域,直接用这些区域的特征作为候选区域的特征即可。这样,我们相当于只在原图上做了一遍卷积操作,而不是每个候选区域做一遍。
除此之外,为了简化训练的流程。作者把 SVM 分类器换成 Softmax,和 CNN 整合成一个网络,同时把 bounding box regression 也整合进网络中(相当于同一个网络同时进行物体判别和区域微调)。这样,可以在保证准确率的同时,提高训练的效率。
Fast RCNN 的改进可以用下面两幅图概括。其中,左图是原 RCNN 的做法,而右图则是 Fast RCNN 的做法。
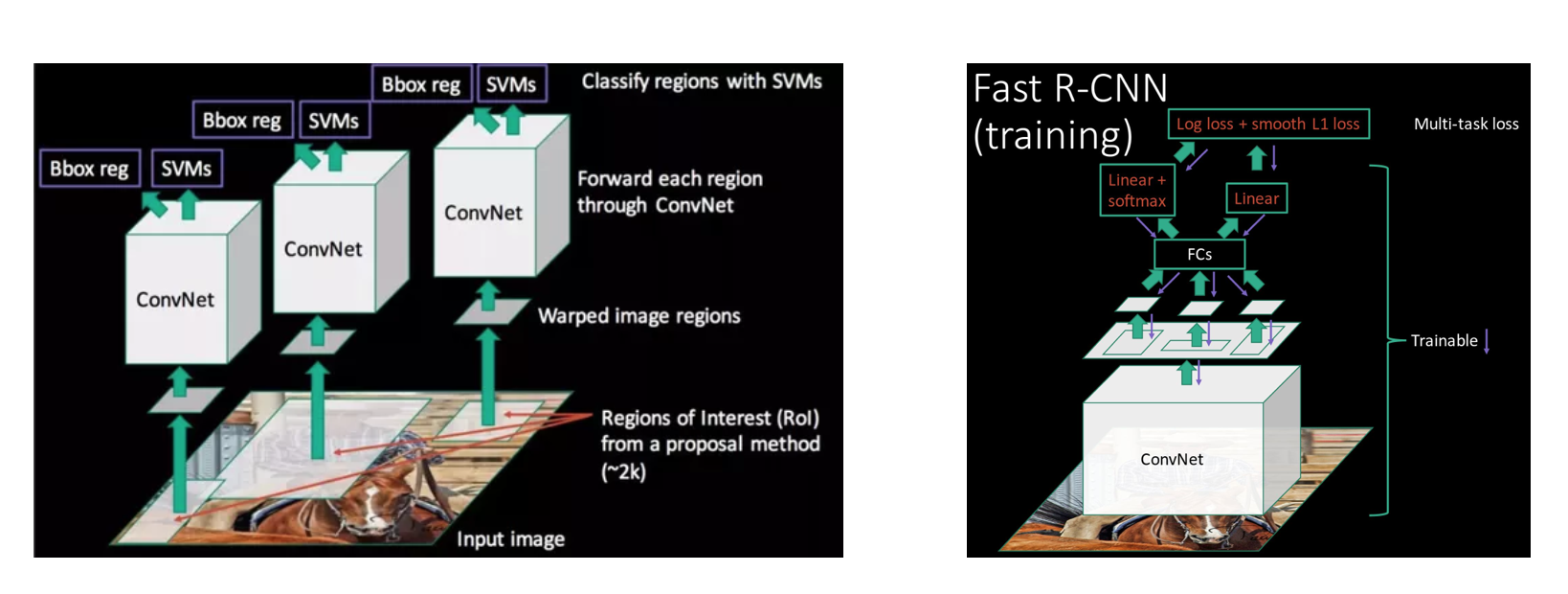
以上两点基本就是 Fast RCNN 所做的改进了。替换 SVM 这一步是很容易实现的,整合线性模型的操作也可以借助 multi-task CNN 的思想实现,但共享卷积操作却会遇到一个严重的问题。因为卷积得到的特征,最后都需要送入全联接层进行降维等操作,而全联接层输入向量的维度必须是固定。由于我们现在是在 feature map 上,根据 SS 提取的候选区域,截取了一小块区域的特征作为该区域的图片特征,因此肯定不符合全联接层的要求(原本的全联接层是针对整个 feature map 的维度进行计算的)。所以下面重点分析一下论文是怎么处理的。
ROI Pooling Layer
为了让全联接层能够接收 Conv-Pooling 后的特征,我们要么是重新调整 pooling 后的特征维度,使它适应全联接层,要么是改变全联接层的结构,使它可以接收任意维度的特征。后者一个有效的解决方案是 FCN(全卷积网络),不过 Fast RCNN 出来之时还没有 FCN,因此它采用的是前一种思路。
那要如何调整 pooling 后的特征呢?论文提出了一种 ROI Pooling Layer 的方法(ROI 指的是 Region of Interest)。事实上,这种方法并不是 Fast RCNN 的原创,而是借鉴了 SPPNet 的思路。关于 SPPNet,网上资料很多,就不再赘述了,所以我开门见山讲一下 ROI Pooling Layer 是怎么处理的。假设首个全联接层接收的特征维度是 \(H \times W \times D\),例如 VGG16 的第一个 FC 层的输入是 \(7 \times 7 \times 512\),其中 512 表示 feature map 的层数。那么,ROI Pooling Layer 的目标,就是让 feature map 上的 ROI 区域,在经过 pooling 操作后,其特征输出维度满足 \(H \times W\)。具体做法是,对原本 max pooling 的单位网格进行调整,使得 pooling 的每个网格大小动态调整为 \(\frac{h}{H} \times \frac{w}{W}\)(假设 ROI 区域的长宽为 \(h \times w\))。这样,一个 ROI 区域可以得到 \(H \times W\) 个网格。然后,每个网格内依然采用 max pooling 操作。如此一来,不管 ROI 区域大小如何,最终得到的特征维度都是 \(H \times W \times D\)。
下图显示的,是在一张 feature map 上,对一个 \(5 \times 7\) 的 ROI 区域进行 ROI Pooling 的结果,最后得到 \(2 \times 2\) 的特征。
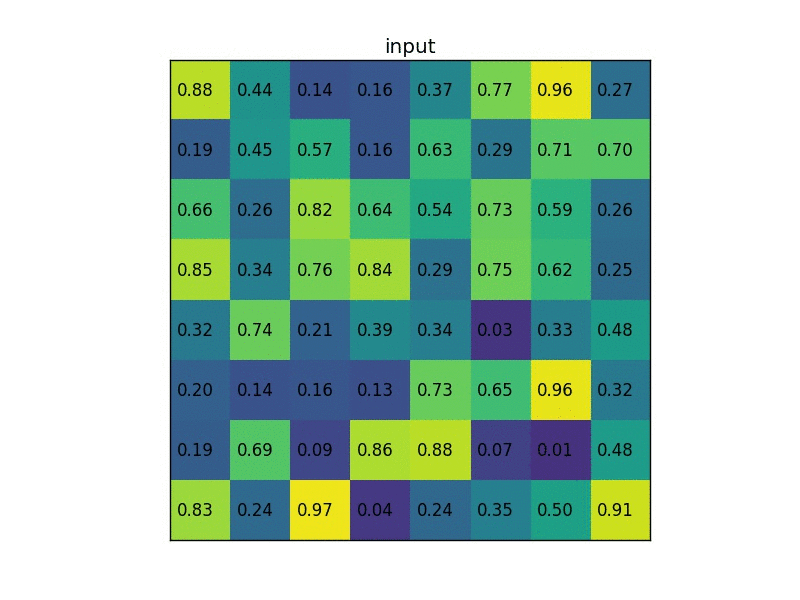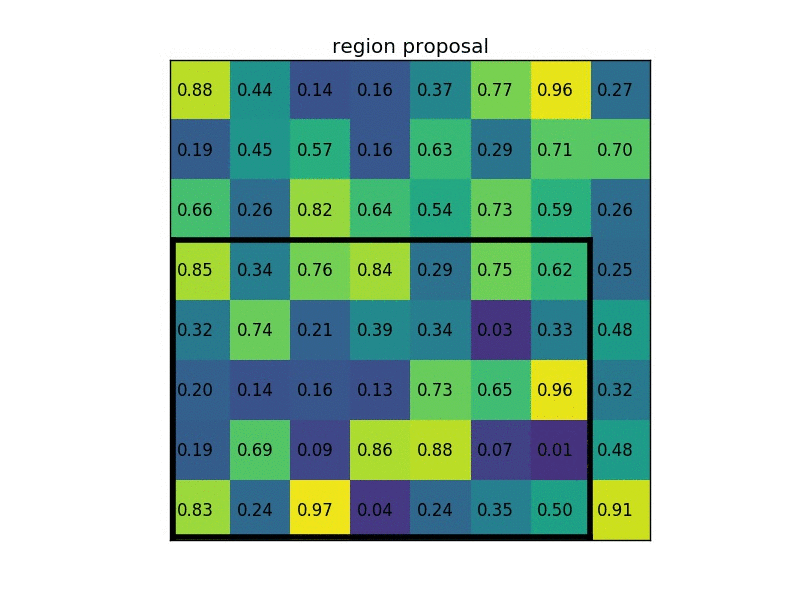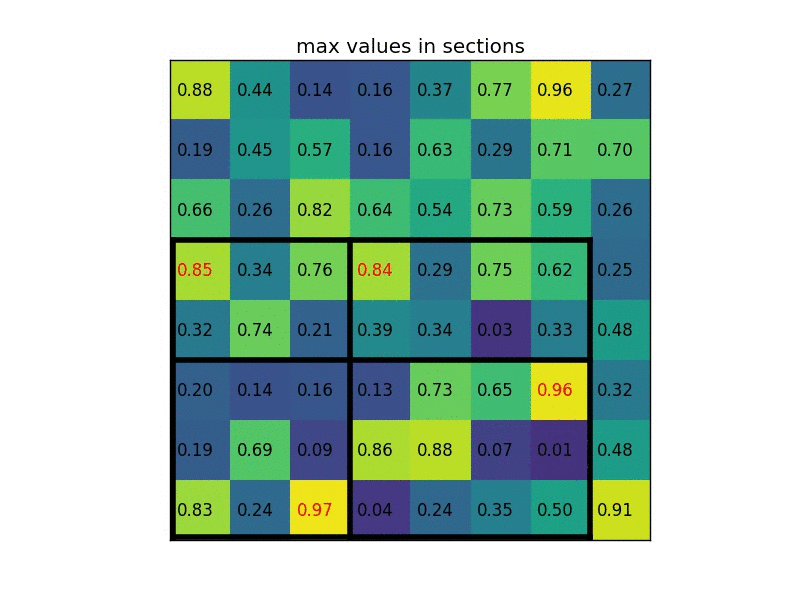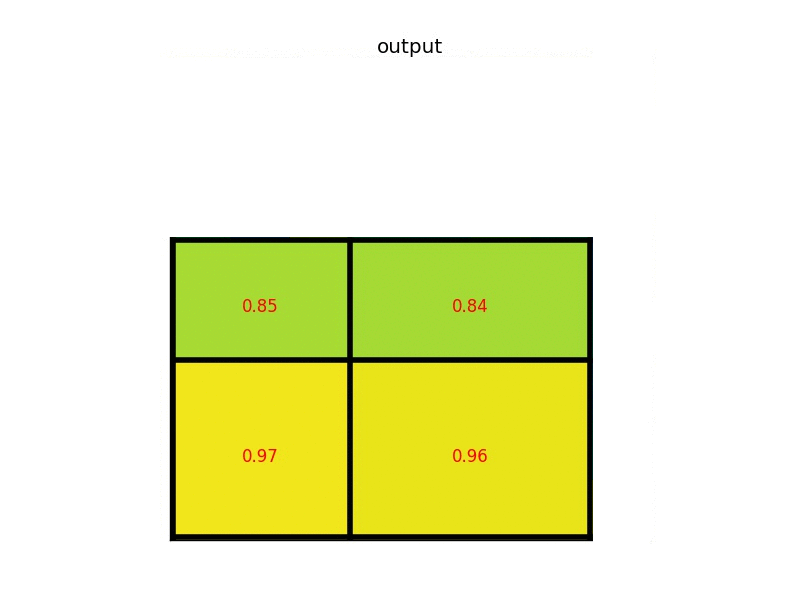
这时,可能有人会问,如果 ROI 区域太小怎么办?比如,拿 VGG16 来说,它要求 Pooling 后的特征为 \(7 \times 7 \times 512\),如果碰巧 ROI 区域只有 \(6 \times 6\) 大小怎么办?还是同样的办法,每个网格的大小取 \(\frac{6}{7} \times \frac{6}{7} = 0.85 \times 0.85\),然后,以宽为例,按照这样的间隔取网格:
\([0, 0.85, 1.7, 2.55, 3.4, 4.25, 5.1, 5.95]\),
取整后,每个网格对应的起始坐标为:\([0, 1, 2, 3, 3, 4, 5]\)。
CNN 学习回归参数
解决 ROI Pooling Layer 后,Fast RCNN 的难点基本就解决了。不过,博主是那种容易钻牛角尖的人,在刚开始看到用 CNN 预测 BBox Regression 时一直疑惑不解。我认为模型拟合的数据之间是要满足因果关系的。假设我们输入的图片中包含一只猫,训练阶段,CNN 在对猫所在的 ROI 矩形区域进行矫正时,它是参考 ground truth 标定的矩形框进行修正的。下一次,假设我们输入同样的图片,只不过图片中猫的位置变化了(猫的姿势等都不变,仅仅是位置变了),那么,CNN 根据 ground truth 进行学习的修正参数,应该跟上一次是一样的,但是,这一次它所参考的 ground truth 却已经换了不同的坐标了,那它又要怎么学习呢?
在查了跟 Bounding Box Regression 相关的资料后,我才发现自己犯蠢了。其实,Bounding Box Regression 学的是一个微调的坐标参数,是一个相对值。也就是说,不管同一个物体在图片中的位置怎么变,网络要学习的,都是相对真实 ground truth 的坐标偏移和尺寸变化,跟物体的绝对位置没有半毛钱关系。
当模型训练好后,对于某一特征,网络已经知道这种特征应该如何调整矩形框了。说得简单粗暴一点,就是网络已经知道,对于 Selective Search 找出来的这种物体,它的矩形框偏离了多少,该如何调整。
(前面这一段说得比较绕,不过应该也没几个人会被这种问题卡住~囧~)
前面说到,Fast RCNN 将物体检测和微调矩形框的任务用一个网络一起学习。其实,就是让 CNN 学习两个代价函数,其中一个用于物体检测,另一个用于 BBox Regression。
物体检测的函数是常见的 Softmax,而 BBox Regression 则是一个比较特殊的函数: \[ L_{loc}(t^u,v)=\sum_{i \in \{x,y,w,h\}}smooth_{L_1}(t_i^u-v_i) \] 其中, \[ smooth_{L_1}(x)=\begin{cases} 0.5x^2 & \text{if |x|<1} \\ |x|-0.5 & \text{otherwise} \end{cases} \] 式中的 \(|x|\) 采用的是 \(L_1\) 范数。\(t^u=(t_x^u, t_y^u, t_w^u, t_h^u)\) 表示预测的矩形框(其实就是 Selective Search 找出来的包含物体的区域),x, y, w, h 分别表示矩形区域的中心坐标以及宽高。而 \(v=(v_x, v_y, v_w, v_h)\) 则是 ground truth。
而网络总的代价函数为: \[ L(p,u,t^u,v)=L_{cls}(p,u)+\lambda[u \ge 1]L_{loc}(t^u,v) \] \(L_{cls}\) 是 softmax 对应的分类损失函数,\(\lambda\) 是一个权重,文中取 1,\([u \ge 1]\) 表示只有矩形框中检测到物体才会执行 \(L_{loc}\) 函数。
Faster RCNN的进击
Faster RCNN,顾名思义,就是比 Fast RCNN 更快。那 Fast RCNN 中,还有什么地方存在短板呢?研究人员发现,检测部分基本都在一个网络中进行了,但候选区域粗提取的工作(region proposal)还是在 CPU 中进行(用 Selective Search)。而 Selective Search 本质上也是对图像特征的分析,那为什么这块分析的工作不直接利用卷积网络运算的结果呢?而且,如果能把所有工作统一起来共同放在 GPU 中进行,不正了了偏执狂们的一桩心愿吗?!于是,人们开始研究,有没有办法用一个网络来取代 Selective Search。这也导致 Faster RCNN 的诞生。
Region Proposal Network
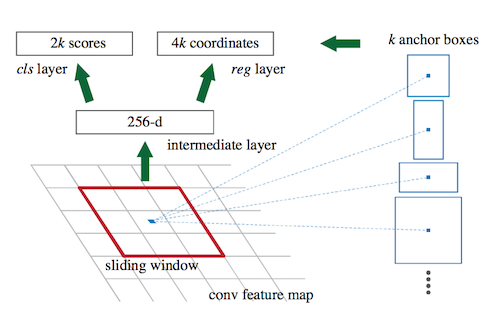
Faster RCNN 提出了一种 Region Proposal Network(RPN),看名字就知道,这个网络是用来提取 region 的。在传统的物体检测算法中,我们一般是用滑动窗口来扫描原图,然后针对每个窗口提取特征。RPN 的思路与之类似,不过,为了共享卷积层的运算,它是在卷积网络的 feature map 上,以每个特征点为中心,用一个 \(n \times n\) 的矩形窗口进行扫描。论文中,n 被设为 3。那我们该如何判断窗口内是否有物体呢?由于卷积网络得到的 feature map 在尺寸上和原图存在一定的比例关系,所以,我们可以把滑动窗口按比例换算回原图,然后对比原图的 ground truth,根据某种事先定好的规则,来判断这个窗口是否包含物体(比如,跟 ground truth 的矩形的 IoU 大于某个阈值就认为包含物体)。在 \(n \times n\) 的窗口之上,论文又用一个 \(n \times n\) 的卷积层,对窗口范围内的 feature map 进行卷积,然后用全联接网络输出二分类的结果(前景还是背景)以及对矩形窗口的粗调整(类似 Fast RCNN 中的 bounding box regression,不过这一步的调整相对粗糙一些)。
上面就是 RPN 的基本思想了。总的来说,可以认为 RPN 就是在滑动窗口上,接着的一个小网络,这个网络会判断窗口内是否有物体,以及会对原图的窗口进行粗调整(原图的窗口是 feature map 上的窗口按比例换算得到的)。
不过,直接根据滑动窗口换算回原图存在一个 bug。试想一下,如果 ground truth 只占这个滑动窗口的一部分(也就是说二者的 IoU 不满足筛选条件),但这一部分又刚好是物体的重要部位,那我们应该认为这个窗口有物体还是没物体呢?
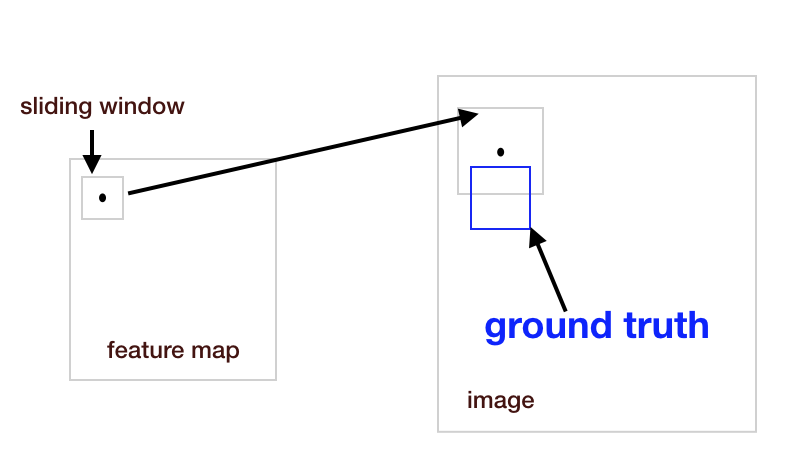
所以,为了防止这种尴尬的事情发生,或者说,为了防止有些窗口被漏捡,我们在换算回原图的窗口时,要尝试不同的窗口尺寸,而不是规规矩矩按照固定的缩放比例。比如,我们可以稍微将原图的窗口调大一些,或调小一些,或将长宽的比例做调整,总之,就是尽可能 match 到窗口内的 ground truth。论文一共试了 k 种组合(实验中,取了 9 种组合,窗口面积为 {128, 256, 512} x 长宽比为 {1:1, 1:2, 2:1})。feature map 上的一个点对应一个窗口,这个窗口内的特征输入 RPN 网络后,最终输出 \(k \times 2\) 个分类结果(表示 k 个窗口分别对应前景还是后景)以及 \(k \times 4\) 个窗口粗调整的结果(表示 k 个窗口应该怎样调整)。论文中,这些原图上的窗口又被称为 Anchor,以便和 feature map 上的滑动窗口区分开。注意,feature map 上的滑动窗口尺寸始终是 \(3 \times 3\),而且每次都只移动一步。有人可能会问,如果滑动窗口对应的 Anchor 中,存在多个物体怎么办?不影响的,因为 RPN 只判断前景跟后景,不做细致分类,而且,RPN 的输出中,k 个窗口会对应 k 个输出。如果有两个 Anchor 对应两个物体,那么,RPN 会将这两个 Anchor 都标记为 前景,并且根据它们各自的输出,微调这两个 Anchor 的位置。
训练的时候,作者随机挑选两张图片,并从每张图片上总共挑出 256 个 ground truth 作为 proposals(包括前景和后景),然后,再根据滑动窗口,挑选出大约 2400 个 Anchors。RPN 的 loss 函数包括两部分: \[ L({p_i}, {t_i})=\frac{1}{N_{cls}}\sum_i L_{cls}(p_i, p_i^*)+\lambda \frac{1}{N_{reg}}\sum_i p_i^*L_{reg}(t_i, t_i^*) \] 其中,
\(L_{cls}\) 是一个二分类函数,
\(L_{reg}\) 则是 bounding box regression 函数(具体的跟 Fast RCNN 一样),
\(p_i\) 表示网络找到的 Anchor 区域中存在物体的概率(1 代表前景,0 代表背景),而 \(t_i\) 则是每个 Anchor 的矩形框位置和大小参数,
\(p_i^*\) 和 \(t_i^*\) 则是 ground truth 对应的前后景概率以及窗口位置,
归一化项中,\(N_{cls}\) 取 batch 的大小(256),\(N_{reg}\) 取 Anchors 的数目(约为 2400)。
总的来说,RPN 可以用下面这幅图表示:
RPN + Fast RCNN
RPN 训练完成后,我们相当于得到一个神经网络版本的 Selective Search。那接下来的工作跟 Fast RCNN 就基本一样了,根据 RPN 找到的 proposal,Fast RCNN 在 feature map 上对这个 proposal 区域的特征进一步分析,判断是什么物体,以及对窗口位置进一步微调。
不过,这其中有很多可以优化的细节。比如,在 RPN 网络之前,我们需要先对图像做卷积操作,而这一部分操作和 Fast RCNN 是可以共享的。这里借用参考博文的一张图来介绍一下整个网络架构。
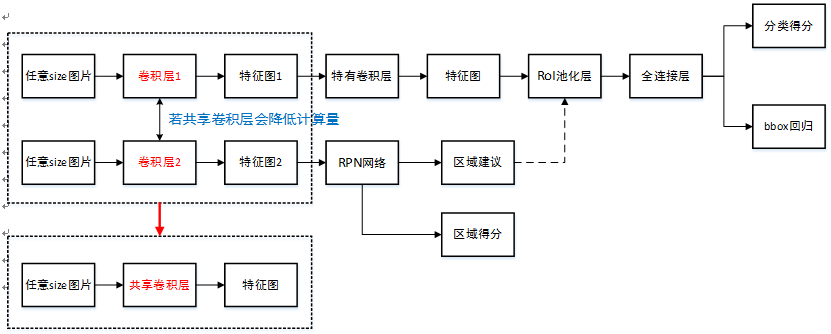
首先,原始图片会经过一个共享的卷积层,得到 feature map。之后,RPN 在这个 feature map 上按照之前的描述提取 proposal,而 Fast RCNN 部分会继续输入到它的卷积层中,得到更高层的 feature map,然后在这个 feature map 上,根据提取到的 proposal,按照 Fast RCNN 的流程判断物体,以及做 bounding box regression。
训练的时候,RPN 和 Fast RCNN 是分开交替进行训练的,这里面涉及到的 trick 较多,很多文章也都有介绍,我这里就不赘述了。预测部分则是一气呵成,不用再经过其他处理,完全实现了 end-to-end。