上一篇文章介绍了量化训练的基本流程,本文介绍量化中如何把 BatchNorm 和 ReLU 合并到 Conv 中。
Folding BatchNorm
BatchNorm 是 Google 提出的一种加速神经网络训练的技术,在很多网络中基本是标配。
回忆一下,BatchNorm 其实就是在每一层输出的时候做了一遍归一化操作:

其中 \(x_i\) 是网络中间某一层的激活值,\(\mu_{\beta}\)、\(\sigma_{\beta}\) 分别是其均值和方差,\(y_i\) 则是过了 BN 后的输出。
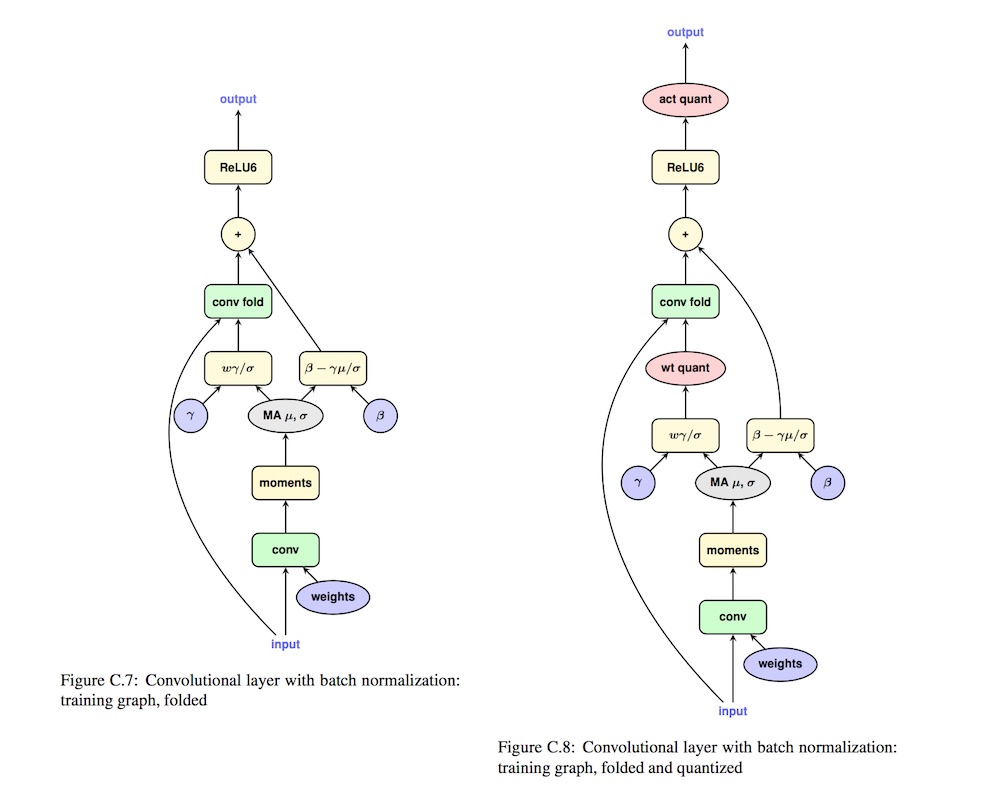
一般卷积层与BN合并
Folding BatchNorm 不是量化才有的操作,在一般的网络中,为了加速网络推理,我们也可以把 BN 合并到 Conv 中。
合并的过程是这样的,假设有一个已经训练好的 Conv 和 BN:
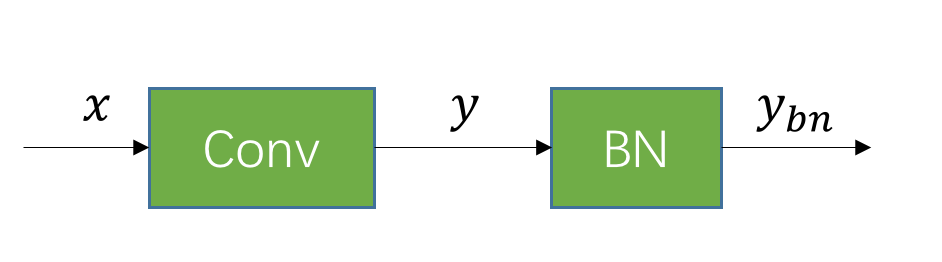
假设 Conv 的 weight 和 bias 分别是 \(w\) 和 \(b\)。那么卷积层的输出为: \[ y=\sum_{i}^N w_i x_i + b \tag{1} \] 图中 BN 层的均值和标准差可以表示为 \(\mu_{y}\)、\(\sigma_{y}\),那么根据论文的表述,BN 层的输出为: \[ \begin{align} y_{bn}&=\gamma \hat{y}+\beta \notag \\ &=\gamma \frac{y-\mu_y}{\sqrt{\sigma_y^2+\epsilon}}+\beta \tag{2} \end{align} \] 然后我们把 (1) 代入 (2) 中可以得到: \[ y_{bn}=\frac{\gamma}{\sqrt{\sigma_y^2+\epsilon}}(\sum_{i}^N w_i x_i + b-\mu_y)+\beta \tag{3} \] 我们用 \(\gamma'\) 来表示 \(\frac{\gamma}{\sqrt{\sigma_y^2+\epsilon}}\),那么 (3) 可以简化为: \[ \begin{align} y_{bn}&=\gamma'(\sum_{i}^Nw_ix_i+b-\mu_y)+\beta \notag \\ &=\sum_{i}^N \gamma'w_ix_i+\gamma'(b-\mu_y)+\beta \tag{4} \end{align} \] 发现没有,(4) 式形式上跟 (1) 式一模一样,因此它本质上也是一个 Conv 运算,我们只需要用 \(w_i'=\gamma'w_i\) 和 \(b'=\gamma'(b-\mu_y)+\beta\) 来作为原来卷积的 weight 和 bias,就相当于把 BN 的操作合并到了 Conv 里面。实际 inference 的时候,由于 BN 层的参数已经固定了,因此可以把 BN 层 folding 到 Conv 里面,省去 BN 层的计算开销。
量化 BatchNorm Folding
量化网络时可以用同样的方法把 BN 合并到 Conv 中。
如果量化时不想更新 BN 的参数 (比如后训练量化),那我们就先把 BN 合并到 Conv 中,直接量化新的 Conv 即可。
如果量化时需要更新 BN 的参数 (比如量化感知训练),那也很好处理。Google 把这个流程的心法写在一张图上了:
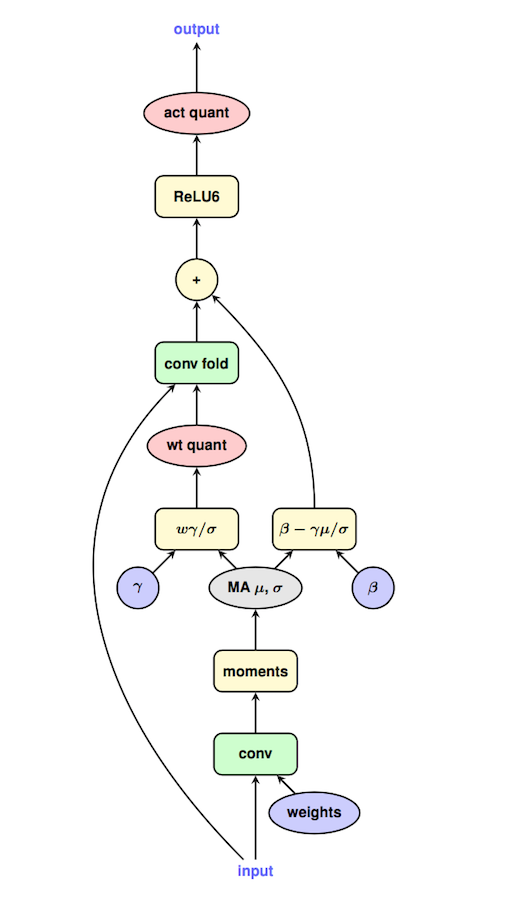
由于实际 inference 的时候,BN 是 folding 到 Conv 中的,因此在量化训练的时候也需要模拟这个操作,得到新的 weight 和 bias,并用新的 Conv 估计量化误差来回传梯度。
Conv与ReLU合并
在量化中,Conv + ReLU 这样的结构一般也是合并成一个 Conv 进行运算的,而这一点在全精度模型中则办不到。
在之前的文章中说过,ReLU 前后应该使用同一个 scale 和 zeropoint。这是因为 ReLU 本身没有做任何的数学运算,只是一个截断函数,如果使用不同的 scale 和 zeropoint,会导致无法量化回 float 域。
看下图这个例子。假设 ReLU 前的数值范围是 \(r_{in} \in [-1, 1]\),那么经过 ReLU 后的数值范围是 \(r_{out} \in [0,1]\)。假设量化到 uint8 类型,即 [0, 255],那么 ReLU 前后的 scale 分别为 \(S_{in}=\frac{2}{255}\)、\(S_{out}=\frac{1}{255}\),zp 分别为 \(Z_{in}=128\)、\(Z_{out}=0\)。 再假设 ReLU 前的浮点数是 \(r_{in}=0.5\),那么经过 ReLU 后的值依然是 0.5。换算成整型的话,ReLU 前的整数是 \(q_{in}=192\),由于 \(Z_{in}=128\),因此过完 ReLU 后的数值依然是 192。但是,\(S_{out}\) 和 \(Z_{out}\) 已经发生了变化,因此反量化后的 \(r_{out}\) 不再是 0.5,而这不是我们想要的。所以,如果想要保证量化的 ReLU 和浮点型的 ReLU 之间的一致性,就必须保证 \(S_{in}\)、\(S_{out}\) 以及 \(Z_{in}\)、\(Z_{out}\) 是一致的。
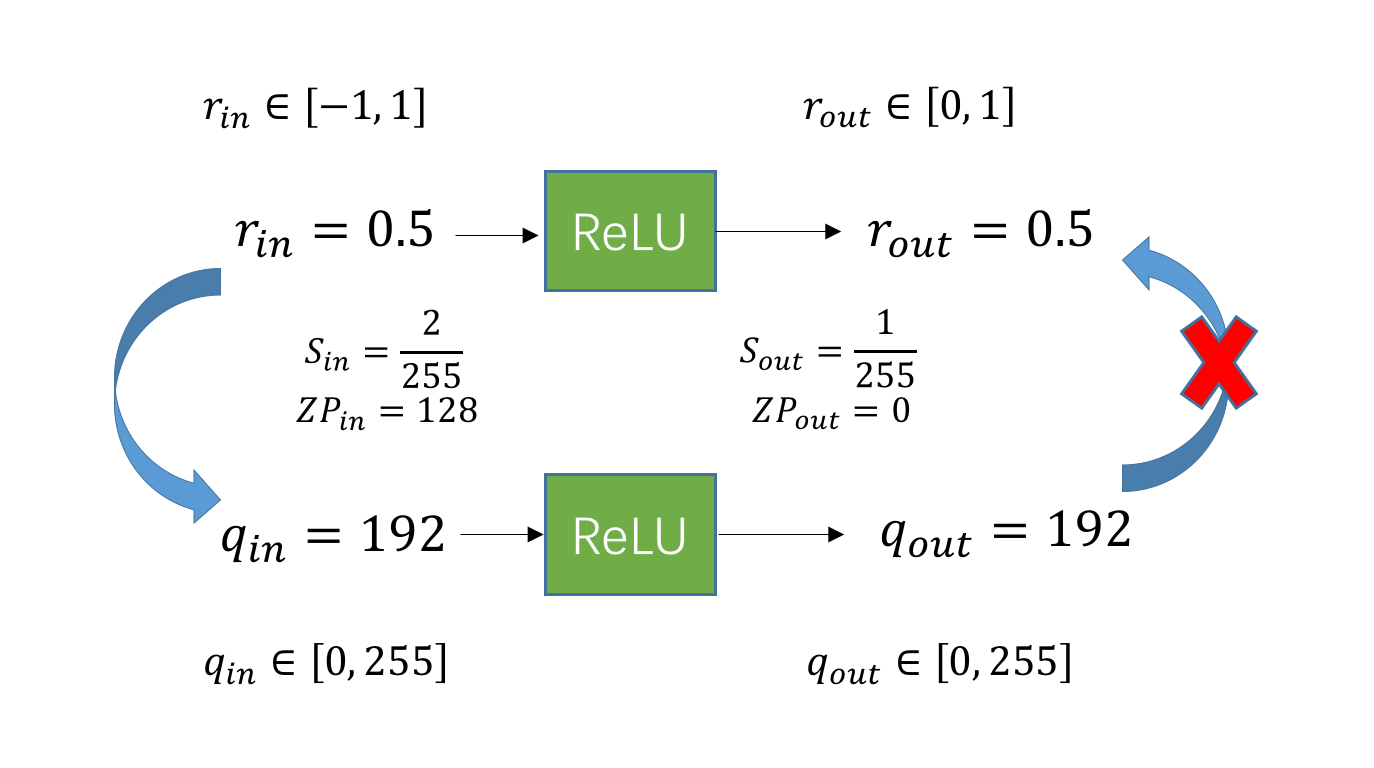
但是保证前后的 scale 和 zp 一致,没规定一定得用 \(S_{in}\) 和 \(Z_{in}\),我们一样可以用 ReLU 之后的 scale 和 zp。不过,使用哪一个 scale 和 zp,意义完全不一样。如果使用 ReLU 之后的 scale 和 zp,那我们就可以用量化本身的截断功能来实现 ReLU 的作用。
想要理解这一点,需要回顾一下量化的基本公式: \[ q=round(\frac{r}{S}+Z) \tag{5} \] 注意,这里的 round 除了把 float 型四舍五入转成 int 型外,还需要保证 \(q\) 的数值在特定范围内「例如 0~255」,相当于要做一遍 clip 操作。因此,这个公式更准确的写法应该是「假设量化到 uint8 数值」: \[ q=round(clip(\frac{r}{S}+Z, 0, 255)) \tag{6} \] 记住,ReLU 本身就是在做 clip。所以,我们才能用量化的截断功能来模拟 ReLU 的功能。
再举个例子。
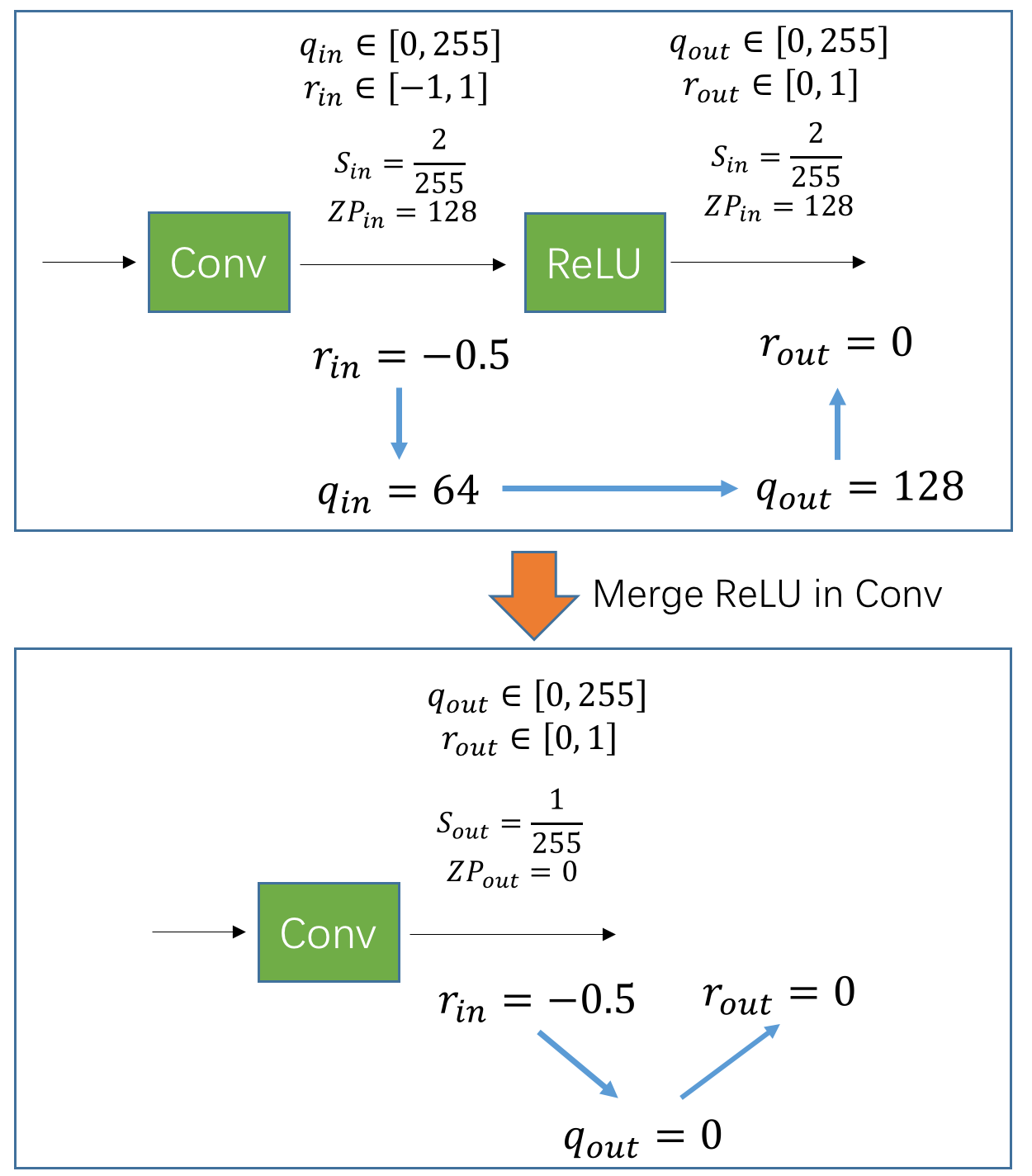
假设有一个上图所示的 Conv+ReLU 的结构,其中,Conv 后的数值范围是 \(r_{in} \in [-1,1]\)。在前面的文章中,我们都是用 ReLU 前的数值来统计 minmax 并计算 scale 和 zp,并把该 scale 和 zp 沿用到 ReLU 之后。这部分的计算可以参照图中上半部分。
但现在,我们想在 ReLU 之后统计 minmax,并用 ReLU 后的 scale 和 zp 作为 ReLU 前的 scale 和 zp「即 Conv 后面的 scale 和 zp」,结果会怎样呢?
看图中下半部分,假设 Conv 后的数值是 \(r_{in}=-0.5\),此时,由于 Conv 之后的 scale 和 zp 变成了 \(\frac{1}{255}\) 和 \(0\),因此,量化的整型数值为: \[ \begin{align} q&=round(\frac{-0.5}{\frac{1}{255}}+0) \notag \\ &=round(-128) \notag \\ &=0 \tag{7} \end{align} \] 注意,上面的量化过程中,我们执行了截断操作,把 \(q\) 从 -128 截断成 0,而这一步本来应该是在 ReLU 里面计算的!然后,我们如果根据 \(S_{out}\) 和 \(Z_{out}\) 反量化回去,就会得到 \(r_{out}=0\),而它正是原先 ReLU 计算后得到的数值。
因此,通过在 Conv 后直接使用 ReLU 后的 scale 和 zp,我们实现了将 ReLU 合并到 Conv 里面的过程。
那对于 ReLU 外的其他激活函数,是否可以同样合并到 Conv 里面呢?这取决于其他函数是否也只是在做 clip 操作,例如 ReLU6 也有同样的性质。但对于其他绝大部分函数来说,由于它们本身包含其他数学运算,因此就不具备类似性质。
总结
这篇文章主要介绍了如何把 BatchNorm 和 ReLU 合并成一个 Conv,从而加速量化推理。按照计划,应该和之前的文章一样,给出代码实现。但我在测试代码的时候发现有一些 bug 需要解决,正好也控制一下篇幅,下篇文章会给出相关的代码实现。
PS: 之后的文章更多的会发布在公众号上,欢迎有兴趣的读者关注我的个人公众号:AI小男孩,扫描下方的二维码即可关注