这一个月来一直在研究计算机美学 (photo aesthetic) 的课题,因为有一个需求是帮助用户筛选出一些拍的比较好的图片。这段时间陆陆续续看了很多相关的文章,也一直在思考这个问题:让计算机来对图片进行审美,到底有没有可能?毕竟审美是一件很主观的事情,美的定义本身也不清晰,让需要明确指令的计算机来做一件人类都不明确的事情,这看起来就不太现实。
本文会记录一下我最近看过的一些文章,总结一下这个领域的研究思路,以及我个人的一些想法。
什么是计算机美学
狭义上讲,计算机美学 (photo aesthetic) 的研究内容是教计算机对图片审美,可以是输出一个分数,也可以是对图片分好坏,抑或是其他评价手段均可以。
当然,更广义的讲,凡是涉及到审美相关的领域都可以归结到计算机美学的范畴。从这个角度出发,可以衍生出大量的课题和应用,比如,让计算机扣图、生成一些非常专业的摄影那个图片等等。
题外话,与计算机审美相关的,还有另一个课题叫图像质量评估 (image quality assessment)。我的理解是,计算机美学偏向于主观感受,而图像质量评估则偏向于客观感受 (比如噪声、饱和度等客观因素)。前者由于太过主观,所以评价指标一般是跟数据集中已有的评分进行比较,而后者则有一些客观的评价标准 (如 PSNR,SSIM)。
下面,我们就根据不同的应用类型,看看各个相关领域的课题都是怎么玩的。
美学评分
最容易想到的应用自然是让计算机给一张图片进行打分。这里的打分可以是输出一个分数,也可以是对图片进行分类,抑或是输出一个美的等级等各种评价手段。前几年很火各种的测颜值 APP,就是美学评分最直接的应用。
这个任务现在来看似乎很简单,无非是将图片丢入一个模型后,再输出一个分数即可。但在没有深度学习的时代,人们通常只能计算一些手工特征(类似颜色直方图、饱和度等),再用一个分类器或回归模型来训练,效果并不好,因而只能是一些实验室 demo,或者在论文中灌灌水。而等到卷积网络大行其道后,美学评分也像其他任务一样,被研究人员从角落里捡起来,加入到各种刷分比赛中,甚至已经被工业界落地成产品。
要想让计算机对图像进行打分,就得先搞清楚美的定义是什么。遗憾的是,对于美的定义,连人类自己都模糊不清,一千个摄影师,就有一千张不同的摄影技巧。因此,为了推动这个领域的研究,人们构造了很多数据集,并且让很多人来对每张图片进行打分,从统计的意义上讲,只要打分的人数足够多,那么平均所有人的评分后,得到的均值就是符合大部分人审美的分数。目前常用的几个数据集包括 CUHK-PQ、AVA、AADB 等,其中被用得比较广的当属 AVA 了,因为这个数据集的图片数量异常庞大,且标签也比较丰富,因此可以挖的点更多。
接下来,美学打分的任务就是在这些数据集上刷分。
下面就简单讲几篇典型的文章,虽然灌水严重,但也不乏启发性很强的好文。
1. RAPID: Rating Pictorial Aesthetics using Deep Learning (ACM MM2014)
这应该算是最早使用深度学习做美学评分的论文了。在图像美学中,图片的整体布局 (global) 和细节内容 (local) 都是需要考虑的因素。为了让网络能同时捕获这些信息,这篇论文除了将整张图片 (global) 输入网络外,还从图片中随机抠出很多 patch (local) 输入网络,然后将二者的信息结合起来进行分类。
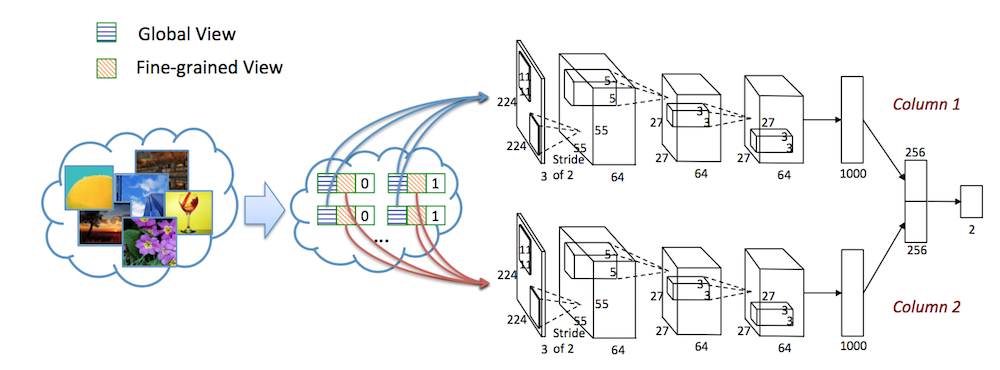
除此以外,由于这篇论文是在 AVA 上做的实验,作者发现 AVA 数据集除了评分外,还有一些 style 相关的属性分数,所以他们也探索了这部分信息的作用。由于不是每张图片都有 style 标签,所以这里面还用了迁移学习的方法来训练一个 pretrain 模型。具体细节不表。
当然,随着网络结构的发展,这篇论文的实验结果早已被超过,但它用 patch 作为输入的做法由于效果不错,因此一直被之后的论文采用。
2. Deep multi-patch aggregation network for image style, aesthetics, and quality estimation (ICCV 2015)
还是上一篇论文的作者,估计他们在之前的尝试中,发现 patch 对这种美学评分的任务效果很好,因此又专门针对 patch 做了一次研究,提出了 DMA 网络。这一次,他们只尝试了用 patch 作为输入,并设计了几种方法来融合这些 patch 的信息:
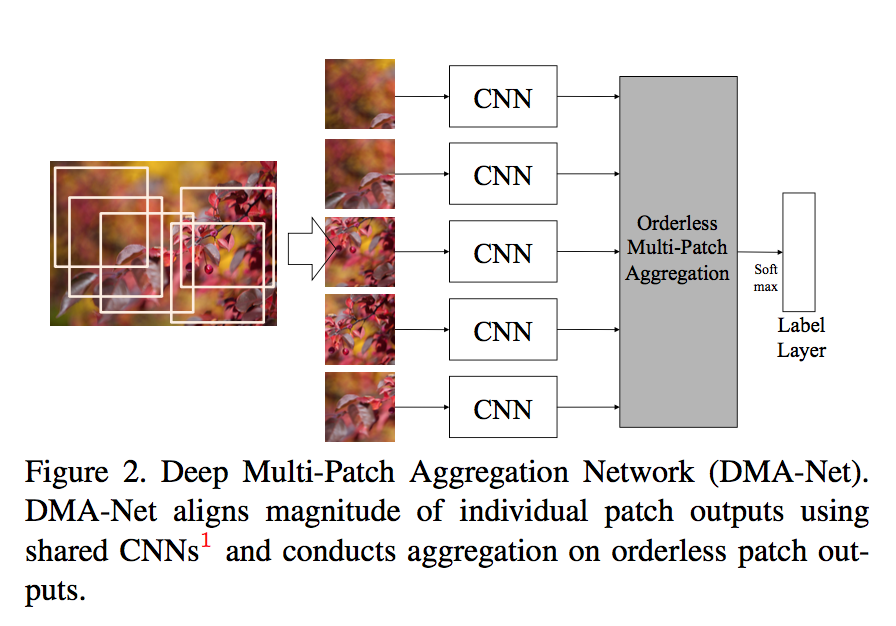
融合 patch 的方法与 MVCNN 很类似,从实验效果来看,将多个 patch 的特征进行融合,比单独输入 patch 的方式,效果提升十分明显。
3. A-Lamp: Adaptive Layout-Aware Multi-Patch Deep Convolutional Neural (CVPR 2017)
这篇论文咋一看标题和摘要,感觉能给很多的 insight,但实际看下去,发现有点 engineering。它是在 DMA-Net (也就是上一篇论文) 的基础上进一步改进的。
在 DMA-Net 中,作者探究了 patch 融合的威力,但他们默认这些 patch 是从图片中随机扣出来的,这样就没法保证 patch 之间不会重叠以及它们能覆盖住图中的关键信息。而这篇论文最大的改进之处就在于,它先用一个显著性检测模型抽取出一些更有代表性的 patch,然后再输入网络中提取特征。
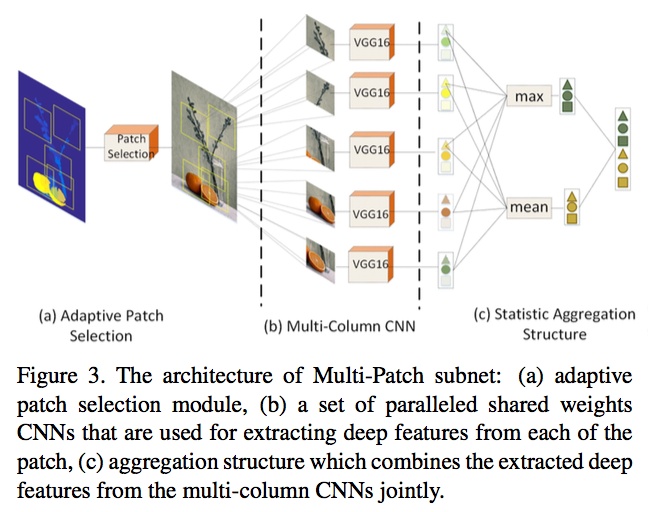
显著性模型抽取到的 patch 可能很多,所以作者设计了几条原则,让程序可以自动筛选出需要的 patch,保证 patch 之间的重叠尽可能小,并尽可能覆盖整幅图的信息。
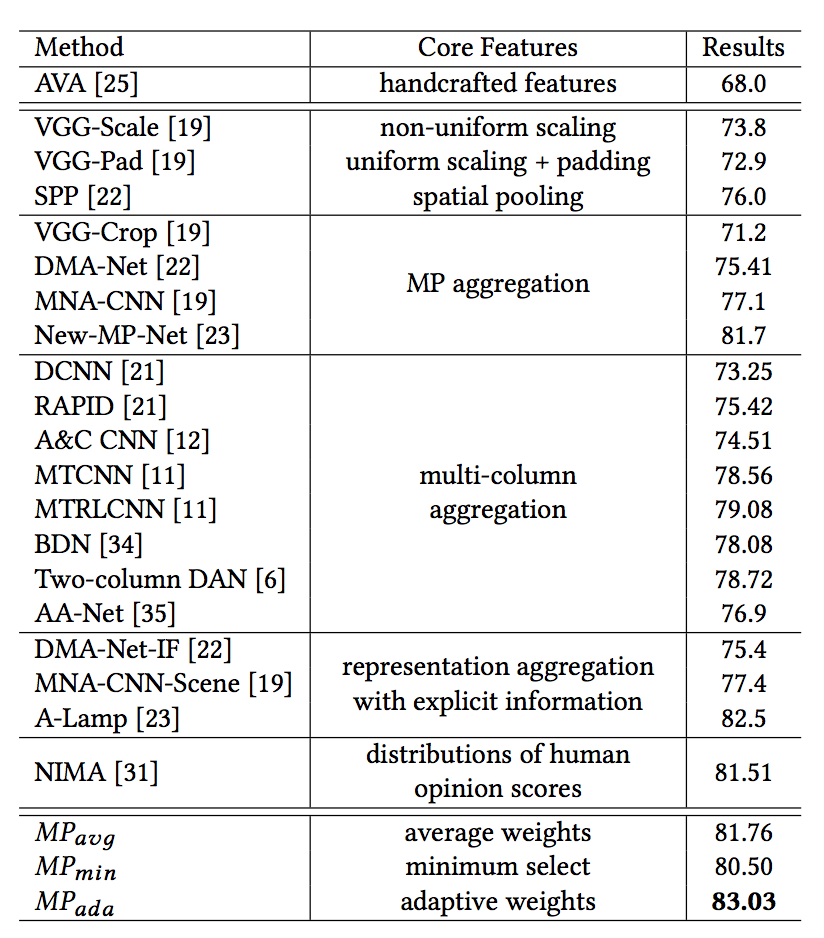
从实验效果来看,选择合适的 patch,对效果会有显著地提升 (图中 New-MP-Net 就是论文的方法):
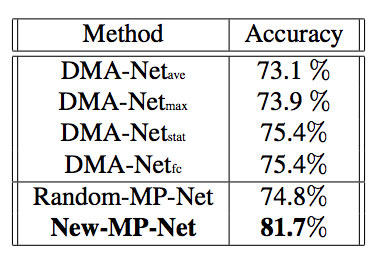
不过,这种方法需要用另一个显著性模型来抽取 patch,在模型方法上不是特别创新,在实际工程中由于计算量太大,也比较难接受。
另外,作者认为图片中物体之间的位置关系会影响图片的布局,而布局又进一步影响审美,所以他们又用另一个显著性模型找出图中的显著性物体,再手工提取出这些物体的位置信息,作为图片的 layout 属性。不过,我感觉这一步并不是很说得通,而且提取特征的步骤也非常的工程 (虽然论文包装得很好),所以这一步就不展开讲了。
4. Attention-based Multi-Patch Aggregation for Image Aesthetic Assessment (ACM MM 2018)
这篇文章同样是针对 patch 的融合方法进行改进。它的 idea 非常简单直接,之前的 patch 融合操作都是采用了 max、min 或者 sort 等操作进行融合,而这篇论文则采用了喜闻乐见的 Attention 机制来计算每个特征对应的 weight,然后根据 weight 把所有特征融合起来。感兴趣的读者可以细看一下原文。
实验方面,也延续了一代更比一代强的传统,在 AVA 数据集上的准确率一举超过了以往的方法:
5. Composition-preserving Deep Photo Aesthetics Assessment (CVPR 2016)
前面说了这么多篇,都是 patch 相关的,现在来看看其他不一样的思路。
在 CNN 中,我们需要将图片调整到固定尺寸后才能输入网络,但这样就破坏了图片的布局。所以,为了保证图片的布局没有变化,就需要将最原始的图片输入到网络中,同时又要让网络能够处理这种变化的尺寸。
为此,这篇论文提出了一种 Adaptive Spatial Pooling 的操作:
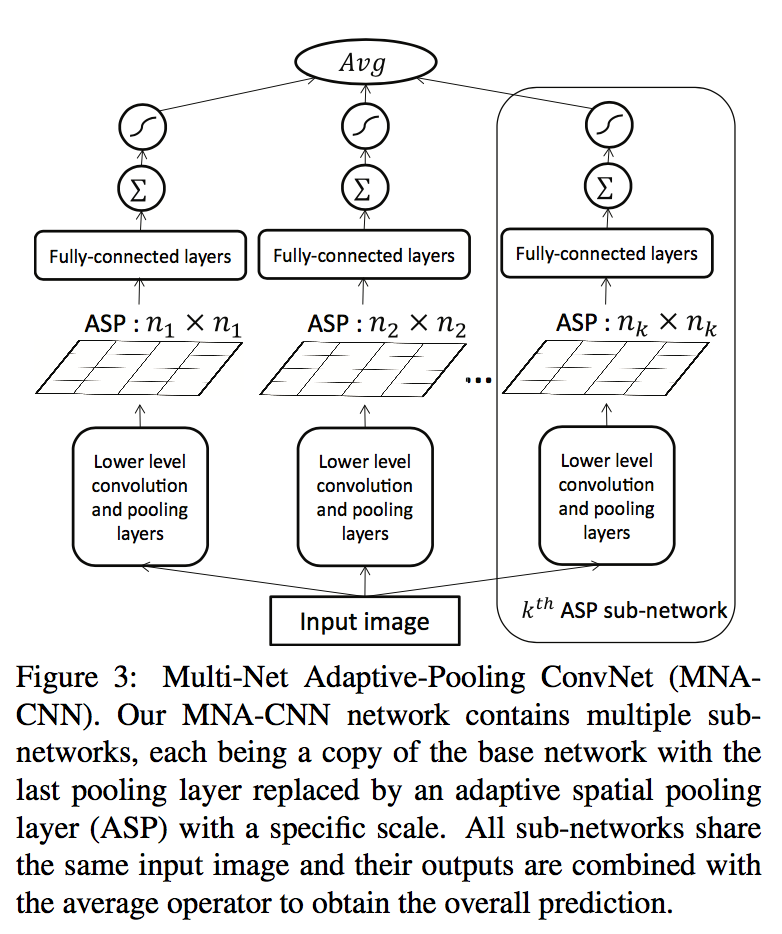
这种操作根据动态地将不同 size 的 feature map 处理成指定的 size 大小。这个操作本质上就是 SPPNet,唯一的区别是 SPPNet 是用一个网络处理图片,并结合多个 Adaptive Spatial Pooling 得到多个 size 的 feature map,而这篇论文则是多个网络结合各自的 Adaptive Spatial Pooling,相当于每个网络提取的 low level 特征会略有差别。
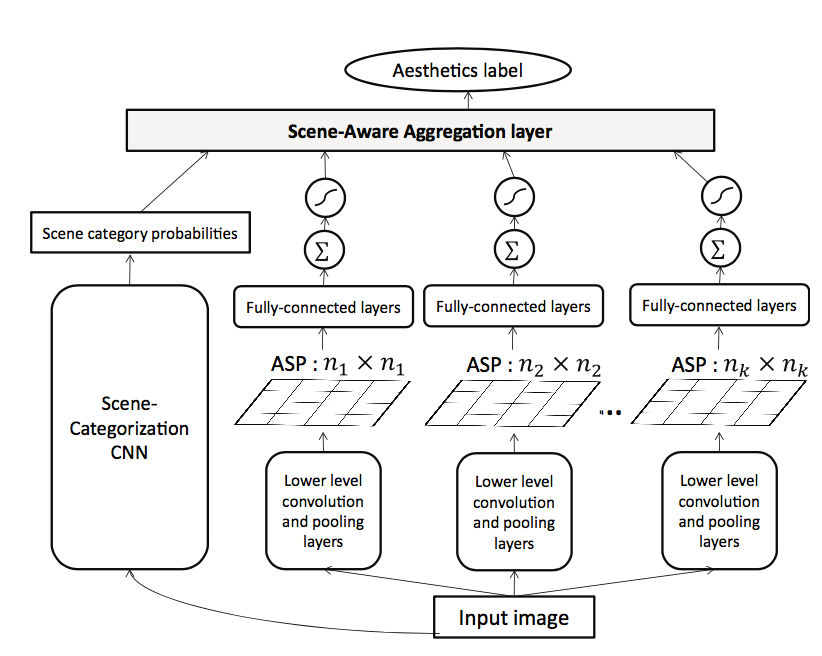
另外,可能作者觉得自己直接拿别人的东西来改网络,工作量不太够,所以他们把场景信息 (scene) 也加入网络中学习。具体地,他们用一个场景分类网络提取图片的场景信息,再融合前面得到的特征作为图片总的特征:
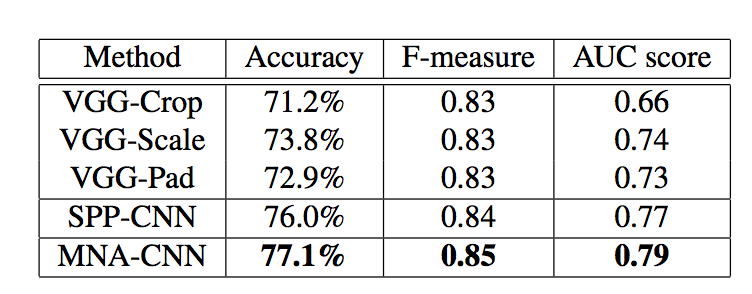
从实验结果来看,保持图片的尺寸,可以让网络学出更好的美学特征 (下图中 VGG-Crop 等实验是将原图进行 crop 等操作后再输入网络):
至于场景信息,从实验结果来看,加成作用并不明显。
6. Deep Aesthetic Quality Assessment with Semantic Information (TIP 2017)
不同的场景往往会有不同的拍照方式和审美标准,因此,把场景的语义信息也融合到网络中,对结果或多或少会有提升作用。上一篇论文虽然也考虑了场景信息,但它用了两个网络来分别提取美学特征和场景特征,因此特征融合的效果未必很好。
这篇论文同样考虑了场景信息,但它用 MTCNN 网络做了一番尝试:
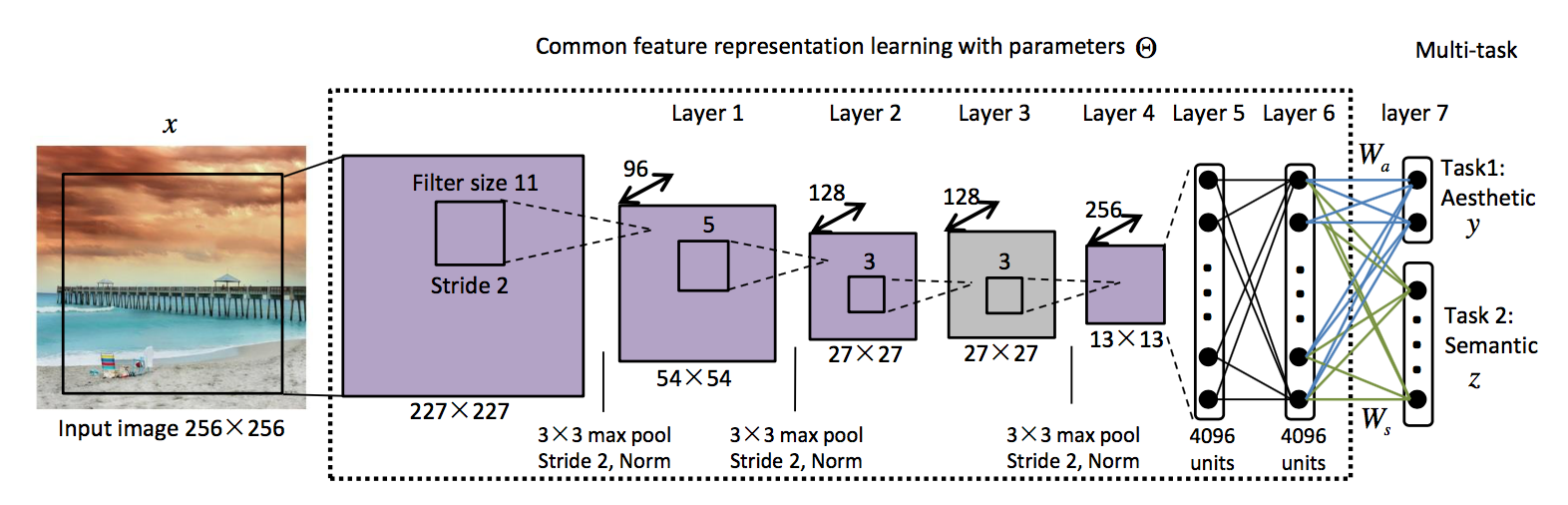
从实验结果也可以看出,这种场景的语义信息可以提高美学分类的准确性 (注:\(\delta\) 表示对好图和坏图的容忍度,具体请参考原论文。STCNN 表示没有加入场景语义信息):

另外,这篇文章针对多任务学习提出了一种 Multi-Task Relationship Learning(MTRL) 的优化框架,分类准确率提高了 0.5 个点左右。
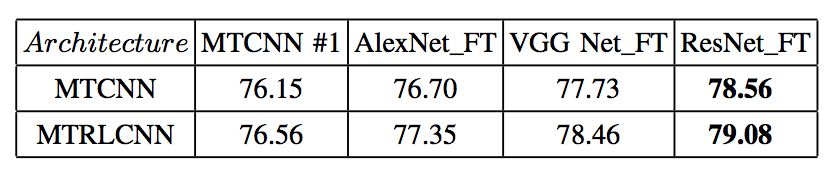
7. Photo Aesthetics Ranking Network with Attributes and Content Adaptation (ECCV 2016)
在之前的论文中,有研究人员已经发现场景信息可以辅助网络学出更好的特征,这篇论文的作者也意识到这一点,不过,他们进一步挖掘出更多的属性特征,包括三分线、内容是否有趣等,为此,他们还特意构建了一个数据集 AADB。这个数据集有一个很有意思的点,就是它记录了每个标注员的 id。对于美学标注这种十分主观的任务来说,不同人的评价标准是不一致的。对于 A、B 两张图片,第一个人可能觉得 A 的分数更高,而另一个人可能相反。这样的标注结果对模型的训练是有害的,尤其是在一些 ranking 相关的任务中。举个例子,假设甲、乙、丙三个人分别对 A、B、C 三张图片打分,结果如下:
| 甲 | 乙 | 丙 | 平均 | |
|---|---|---|---|---|
| A | 5 | 5 | 1 | 3.66 |
| B | 1 | 2 | 5 | 2.66 |
| C | 2 | 5 | 5 | 4 |
从平均分可以看出,A、C 的评分很接近,而 C 的分数要明显高于 B,因此单从平均分排序的话,A 和 C 可能被分为一档,而 B 是单独一档。但单独看每个人的打分,情况却是这样的:
| 甲 | \(A > B = C\) (A 的评分明显更高,B、C 仅相差一分) |
|---|---|
| 乙 | \(A = C > B\) |
| 丙 | \(B = C > A\) |
因此如果单纯用平均分让网络进行排序,可能会丢失很多信息。所以,在 rank loss 中,作者针对每个标注人员各自的评分采样 pair,比如,对于甲而言,采样到 A、B 两张图的评分就是 (5,1),而不是平均分的 (3.66,2.66)。这样,网络对 A、B 两张图的区分能力可能会更大。当然,从甲乙丙各自的评分来看,不同人的评分可能是矛盾的,因此这种采样方式也未必能训练好网络,但这种思路还是值得借鉴的,只是方法可能可以再改进一下。
这篇文章总共采用了 regression loss 和 rank loss 两种损失函数,因此从网络结构上看,是一个明显的 multi-task 的结构:
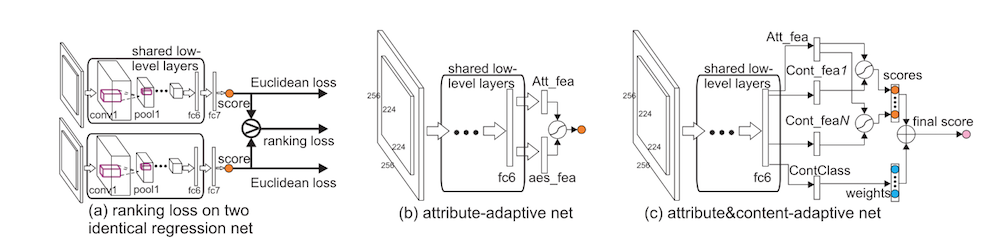
实验结果请参考原论文。
8. NIMA: Neural Image Assessment (TIP 2018)
前面的文章要么是在网络结构上改善,要么是引入新的信息帮助网络进行训练,这篇文章从损失函数的角度,改进模型的训练。
在 AVA 数据集中,每张图片都被分为 10 个分数等级,并由 250 位以上的标注员进行打分,每个人可以选择 1~10 中的一档。因此,每张图片的分数其实可以用一个柱状图来表示。
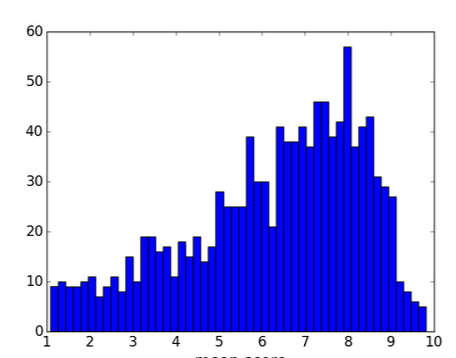
在之前的论文中,研究人员都是将这 10 档分数分为好坏两段 (0~5 和 5~10),这么做其实是把很好 (差) 的和比较好 (差) 的等同看待,从信息的角度来说是比较浪费的。
因此,为了利用上这部分信息,这篇论文在损失函数上进行了改进。作者让网络输出这 10 档分数的直方图分布:
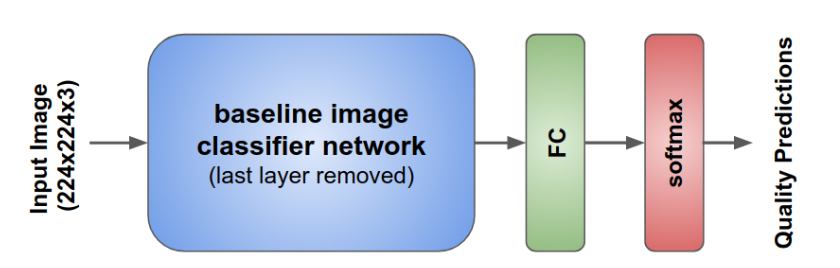
再采用 Earth Move Distance 来衡量网络输出与真实的直方图之间的距离,以这个距离作为损失函数进行训练。Earth Move Distance 可以理解为 Wasserstein Distance 的离散版,可以用来衡量两个分布 (直方图) 的距离。具体计算方法请参考论文。
在实验效果上,也基本超过了当时最好的方法:
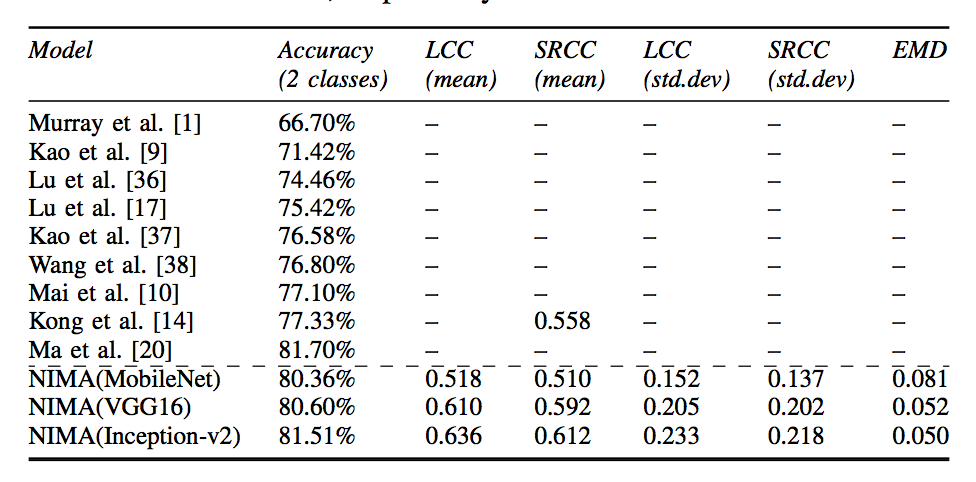
这篇文章来自 Google。相比起前面提到的论文,它最大的优势在于整个框架非常简单直接,效果不错,在工程上应用性更强。这也是 Google 一贯的作风。
9. Predicting Aesthetic Score Distribution through Cumulative Jensen-Shannon Divergence (AAAI2018)
这篇论文同样是在损失函数上做文章。与 NIMA 这篇论文相似之处在于,作者同样注意到要对 AVA 的直方图信息进行利用。因此,他们根据 JS Divergence 提出了一种衡量两个分布 (直方图) 差异的方法,并以此作为损失函数优化网络。具体细节请参考原文。
图片美化
前一节讲的美学评分其实是计算机美学里的关键问题,是众多美学任务中的基本任务。让计算机学会给图片打分,其实就是让计算机对好的和坏的图片做出大致的度量。一旦计算机可以学会这种度量,就可以进一步引导其他相关的任务。比如,对一张很差的图片进行美化。
1. Aesthetic-Driven Image Enhancement by Adversarial Learning (ACM MM 2018)
这篇论文,顾名思义,就是从美学的角度对图像进行增强。在以往大多数的研究中,图像增强一般需要成对的样本 (即需要 ground) 进行训练,但这需要大量的标注工作 (比如让专业人员用 PS 将低质量的图片处理成高质量的图片,当然有一种 trick,即反过来,我们先搜集大量高质量的图片,再用软件随机加噪声或者降低饱和度等等,从而批量制造低质量的图片)。图像增强的本质就是将一种图片转换成另一种图片 (类似 image-to-image),之所以需要成对训练,就在于计算机不明白低质量和高质量这两种模态的差异,因此只能用成对的图片让它学会这种图片与图片之间的映射。而如果计算机本身能识别出好图和坏图,那可以认为它已经知道了如何去度量高质量和低质量图片的差异,这样的话,就可以用弱监督学习的方式,不需要借助成对图片进行训练了。 (通常用 GAN 作为训练方法)。
本文的核心思想就在于此。它采用 GAN 作为训练方式 (这也是这类弱监督学习的常用方法)。作者从颜色变换的角度,设计了一个生成网络对低质量图片进行增强,然后,他们又设计了一个判别器网络来分辨生成的图片以及其他真实的高清图片。
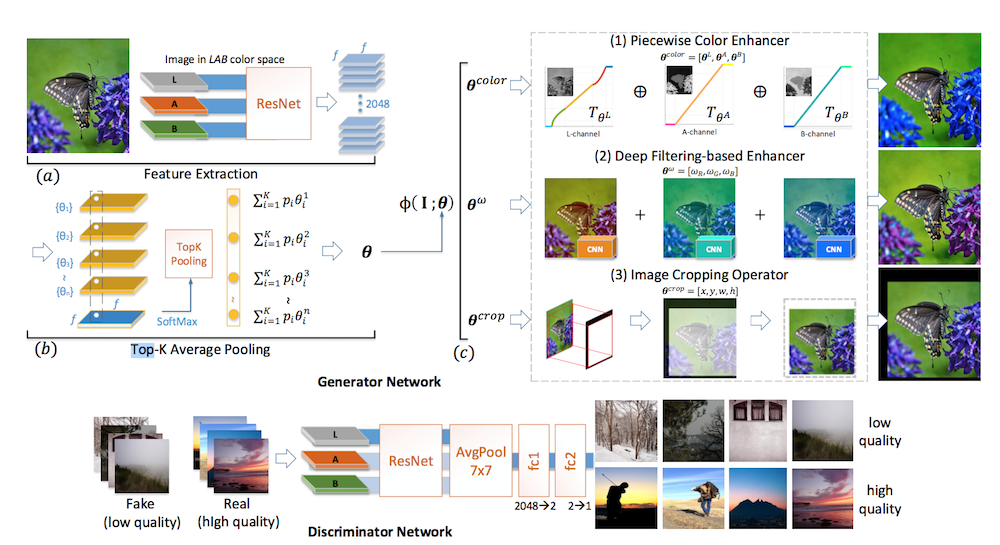
这里的判别器本身不是一个随机初始化的网络,而是已经训练过,能很好地识别低质量和高质量图片的模型。因此,这个判别器本身可以度量这两个分布之间的差异,它可以进一步引导生成器学习,从而摆脱对 ground truth 的依赖。
2. Creatism: A deep-learning photographer capable of creating professional work (arXiv 2017)
这篇论文出自 Google 之手,事实上并没有正式发表,但从结果来看,确实非常的惊艳👇

这篇论文主要做的是一个自动后期处理工具。说的直白点,就是学习一个滤波器对图片进行增强。论文最值得借鉴的做法就是把整个图像增强的任务分解为一系列互不影响的滤波器,通过把这些滤波器串联起来,完成最后的增强效果。这其中,有的滤波器负责调整饱和度,有的负责调整光照,有的裁剪图片调整构图,等等。而为了让这些滤波器互不影响,在训练的时候,需要针对不同的滤波器,用不同的数据进行训练。举个例子,在训练饱和度相关的滤波器时,我们先用一些图像处理工具,只针对饱和度这一点在原图上进行修改,这样就得到修改前和修改后的一对图片,再根据这对图片来训练饱和度相关的滤波器。其他滤波器也同理。这种用一对图片、并针对某个因素单独训练的方法,相比上一篇论文而言,可以降低模型学习的难度。当然,这样训练的前提条件是我们手头上要有质量很高的图片,如此一来才能通过一些图像处理软件进行处理,批量得到质量很差的图片,从而用一对图片进行训练。
论文的另一个难点在于对图片进行打光处理。在自然环境下,物体反射的光并不是均匀的,受材质、光源等各种因素影响,总是有部分地方的光比较亮,有部分地方的光比较暗。比如下面这张图片,由于云遮挡了阳光,导致部分山体的光线偏弱。适当的光照,可以让图片质量提升一个档次。

不过,这里我们没法再套用前面的方法来生成一对图片样本了。因为光照本身是一个很复杂的东西,如何用软件来批量添加或去除光照,本身就可以当作一个课题研究了。既然没法用软件来处理,那就只能换种训练方式了。论文采用 GAN 的弱监督学习方法,来训练光线处理的滤波器。举个例子,我们假设现在手上拥有的图片都是一些光照处理非常好的图片,接着,我们可以用图像处理工具大幅度的降低这些图片的亮度。注意,这种降低对所有像素是「一视同仁」的,并不会刻意区分哪些区域应该更低,哪些区域应该更亮。然后,我们用一个生成网络来生成一个光照的 mask,把它作用到这些亮度很低的图片上进行打光,并用一个判别器网络来区分原图和这些打光后的图片。通过这种博弈的方式来训练生成网络。只要训练得好,最后生成器就能生成出一个打光效果最好的 mask,这个 mask 会告诉我们哪些地方亮度要更高,哪些地方亮度要更低。下图分别是打光前、mask 以及打光后的图片效果:

更具体的细节,还请参考原论文。
自动裁剪
自动裁剪,就是在图片中裁出一块区域,这块区域要么构图很好,要么包含最主要的内容,总之,裁出来的这块图片总体上比原图要更加赏心悦目。在计算机美学出现的同时,图片自动裁剪作为一种衍生品也在不断发展。工业界中已经有相关的产品落地,比如 iphone xs 的相册中,有一个功能是对相册图片进行裁剪,并把裁剪出来的图片以幻灯片的形式做成视频,还有常见的缩略图功能也会用到自动裁剪的技术。
目前,自动裁剪技术的实现方案局限在两种思路上。第一种,借用注意力机制 (或者显著性物体检测),裁剪出图片中最重要的部分;第二种,借助计算机美学评分,在众多滑动窗口中选出美学评分最高的窗口进行裁剪。
1. Learning the Change for Automatic Image Cropping (CVPR 2013)
这篇论文可以算是深度学习兴起前,传统方法的典型作品了。其思路就是人工定义很多的规则抽取 feature,再用 SVM 等工具进行训练,测试的时候再暴力遍历很多窗口,把分数最高的作为最好的裁剪窗口。在特征提取上,这篇论文融合了显著性检测和美学评分两种思路,先把图片分成前后景,再根据前后景之间的颜色差异、纹理差异、显著区域的位置关系等多种规则提取特征 (由于这篇论文关注的是前后景之间的差异,所以叫 learning the change),然后训练模型。在测试时,结合一些启发式搜索的策略,可以剔除掉大量候选窗口,以此提高算法的速度。
另外,这篇论文还构建了一个包含 1000 张图片的数据集。
2. Automatic Image Cropping for Visual Aesthetic Enhancement Using Deep Neural Networks and Cascaded Regression (TMM 2017)
这篇论文算是深度学习在自动抠图方面的早期尝试了 (虽然论文发表于 2017 年,但由于是期刊论文,所以实际成稿时间会早很多)。它的基本思路非常简单,就是先初始化一个矩形框,用 CNN 提取矩形框内图像的特征 (由于矩形框大小不一,为此还用了 SPPNet 的技术),之后用回归模型来拟合特征和 ground truth 中矩形框的坐标。这里的 CNN 是在 AVA 和 CUHK-PQ 等数据集上预训练过的。在回归模型中,采用的损失函数是 MSE Loss。这里面,CNN 和回归模型的训练是分开的,之所以要这样做,是因为当时的数据量非常有限,论文当时实验的数据集就是上一篇论文采集的 1000 张图片,因此并不具备训练 CNN 大模型的条件。在回归模型方面,作者采用了 gradient boosting 的方法逐次训练若干个回归器,每个回归器的输出是对矩形框位置的微调系数,由于是 boosting 的思路,所以每个回归器也是在上一个回归器的基础上进一步训练微调的。
具体细节可参考原文。在数据量突飞猛进的今天,学术界和工业界更普遍的做法是用一个完整的模型实现端到端的训练。
3. Deep Cropping via Attention Box Prediction and Aesthetics Assessment (ICCV 2017)
回想我们人类自己在裁剪图片的时候,都是先找出最重要的一块区域,框起来,再逐步调整这个裁剪框。这篇论文把这个过程建模为两步:首先,让网络找出图片中最重要的区域,并微调,由此得到一系列候选框,紧接着,用一个美学评分模型对这些候选框进行挑选,找出评分最高的候选框。这个思路跟其他论文的做法没有本质区别,但由于它在找候选框的过程中借用了物体检测的思想,跟其他基于显著性检测或者启发式搜索的方法不同,再加上它把整个论文的 motivation 跟人类自己的操作流程结合起来,因此显得很新颖。
论文的算法框架分为 ABP(Attention Box Prediction) 和 AA(Aesthetics Assessment) 两个网络。前一个网络用于生成候选框,后一个网络用于打分。ABP 网络的训练需要大量的候选框 ground truth 作参考,由于作者是从注意力的角度出发定义的候选框,因此他们采用了一个视觉注意力相关的数据集 SALICON 来生成 ground truth。除了包围注意力区域的候选框外 (下图 c),再根据 IOU 生成更多的正候选框 (注意力区域) 和负候选框 (背景区域) (下图 d),以此获得大量的训练样本。

之后,他们用这些候选框来训练 ABP 网络:
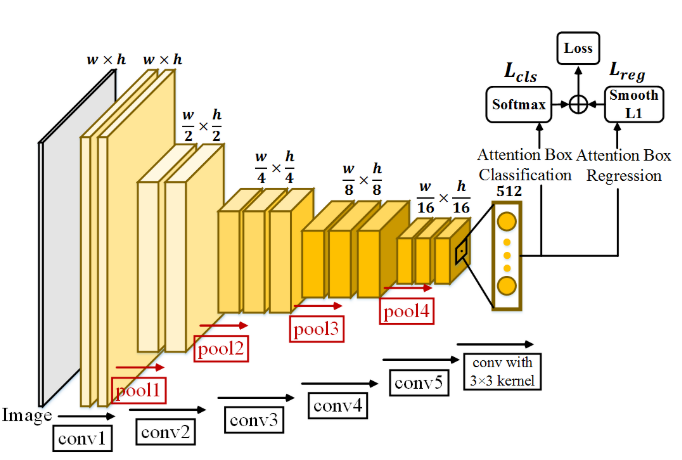
整个网络的结构和损失函数的设计,像极了 Faster RCNN。有了 ABP 网络后,我们就可以根据预测的概率分数选出最好的候选框,不过,为了防止这一步出差错,作者把这个候选框适当增大,获得更多候选框,之后,就是用 AA 网络来预测每个候选框的分数。
这篇论文的工作量有点大,毕竟 Faster RCNN 本身就不是简单的东西。但看完后我总感觉有点南辕北辙。论文是先预测 Attention Map 所在的候选矩形框,然后再用 AA 网络挑选最好的,那为何不直接让网络预测 Attention Map,再根据 Attention Map 来生成候选矩形框呢?没想通。。
4. A2-RL: Aesthetics Aware Reinforcement Learning for Image Cropping (CVPR 2018)
这篇论文从强化学习的思路入手解决自动裁剪的问题。
自动裁剪的过程可以理解为不断地调整矩形框,直到获得较高的美学评分。这就是一个不断试错的过程,和强化学习本身的工作原理非常类似。由于我对强化学习一窍不通,具体算法请查看原文。
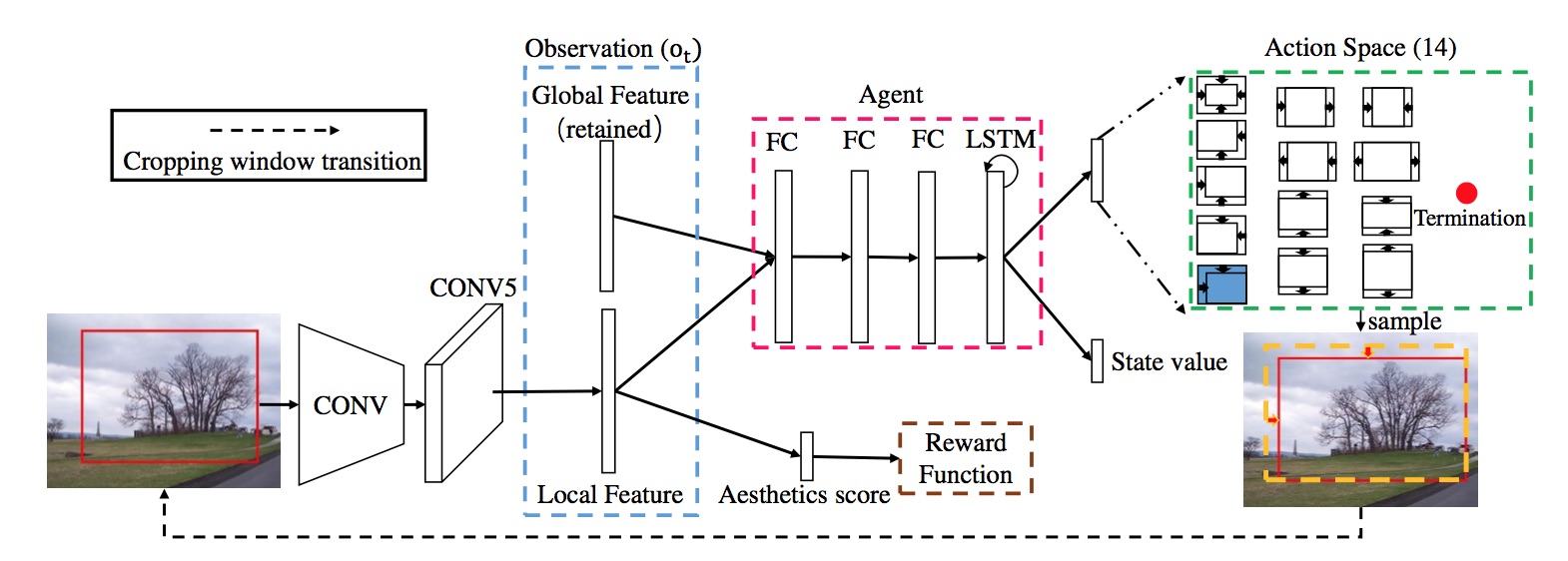
5. Reliable and Efficient Image Cropping: A Grid Anchor based Approach (CVPR 2019)
这篇论文的核心思想都在题目的 Reliable 和 Efficient 两个词中,即裁剪出来的区域必须是真的好看的(Reliable),而且裁剪的过程要足够的高效,不能花太长的时间(Efficient)。
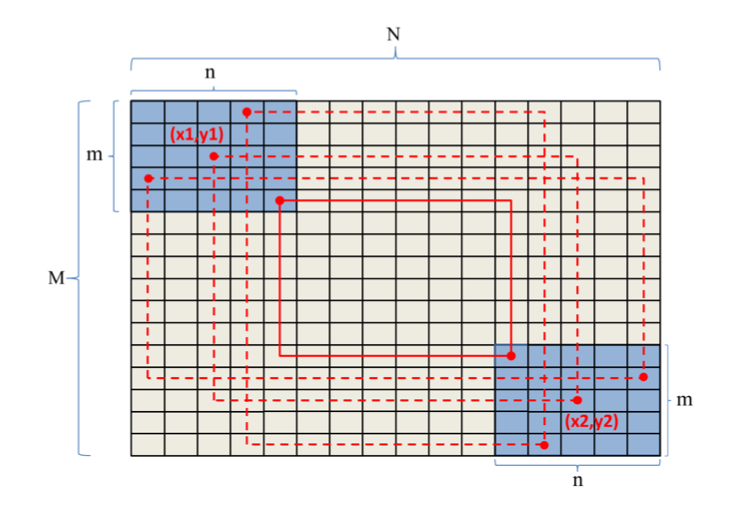
那如何评价是否 Reliable 呢?之前的方法都是将模型输出的裁剪框跟数据集中的 ground truth 计算 IoU 以及裁剪框四个坐标点的差值,这很明显是采纳了物体检测中的评价标准。但对于图片裁剪来说,这并不是一个特别好的评价标准。理由见下面这张图的最后一列。

因此,论文提出了两个新的评估指标:SRCC (Spearman’s rank-order correlation) 和 \(Acc_{K/N}\) (return K of top-N accuracy)。
SRCC 是衡量两个排序相关性常用的指标。虽然 IoU 没法衡量裁剪框的可靠性,但对于同一张图片来说,模型输出的所有裁剪框之间的好坏关系大体还是要跟 ground truth 匹配上的。在实际使用时,需要把 ground truth 中标好的矩形框让模型来一一打分,然后用 SRCC 计算这些矩形框的分数高低跟真实标定的分数的一致性。
\(Acc_{K/N}\) 则是这篇论文提出的一种计算方式。在实际应用中,用户更在意的可能是算法输出的若干个裁剪框中有多少个是真正合理的。因此,可以比对一下 ground truth 标记分数最高的前 N 个裁剪框以及模型计算得到的分数最高的前 K 个裁剪框,看看这个交集有多大。交集越大,证明模型输出的裁剪框质量越好,模型的可靠性就越高。
解决 Reliable 问题还需要有一个质量非常高的数据集,毕竟算法是没法知道美丑的,只能通过数据本身来告诉它。论文构建了一个包含 1236 张图片,总共标记有 106860 个裁剪框的数据集(GAICD),其中每个裁剪框都包含有若干个人的打分,根据他们的平均值作为每个裁剪框的美学分数。
针对算法效率的问题,这篇论文采用的方法是人为制定一些规则来限制裁剪框的位置。由于图片中的主体或者主要内容一般位于中间位置,因此可以把裁剪框的位置「大致」固定在中间,并设定它的面积应该大于某个阈值。由此可以将裁剪框的搜索面积大比例缩小。
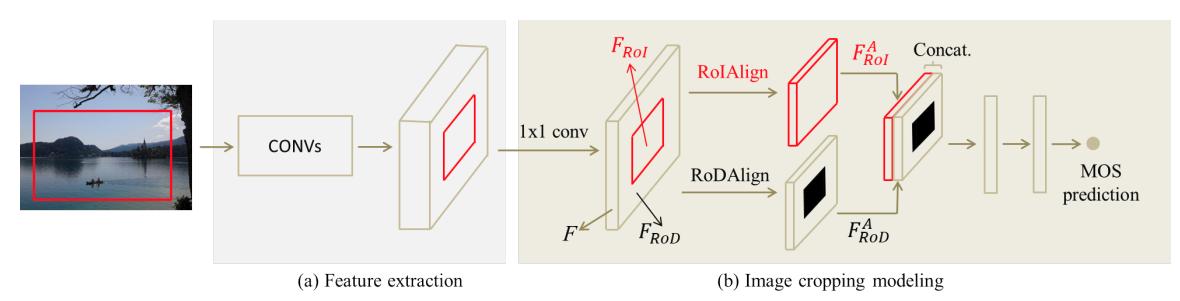
下图是论文算法的总体框架,由于裁剪框已经事先定义好了,因此只要逐个预测裁剪框内的分数即可。总体模型就是一个回归模型。作者先用一个网络提取整张图片的特征,并在最后的特征图上,根据裁剪框内的区域计算分数。由于分数预测的模块比较小,即使要计算的矩形框很多,总体花费的时间并不大。这里用到一个 trick:由于构图这个东西除了考虑裁剪框内的因素外,还需要考虑框内的元素在整幅图中的效果,即需要兼顾 local 和 global 的信息,因此在计算分数的时候,作者把裁剪框内的 feature 以及整幅图 (挖掉裁剪框内的部分) 的 feature 结合在一起,共同输入网络中计算 (不过这样没法体现位置信息,因此对这种做法我持保留态度)。
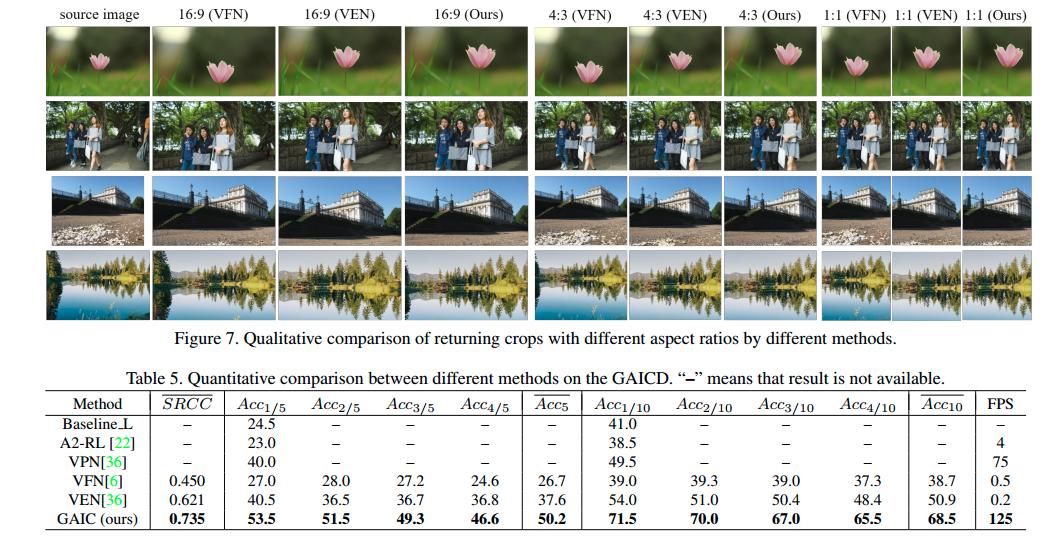
从实验结果来看,这篇论文的算法效率有很大的优势,裁剪效果也不差:
自动构图
自动构图 (Compose) 与自动裁剪 (Crop) 本质上属于一个东西,都是让计算机从图片中找出更好看的区域。但相比较而言,自动构图更侧重于美学中的构图因素。
1. Learning to Compose with Professional Photographs on the Web (ACM MM 2017)
这篇论文的思路基于一个简单的假设:专业摄影师拍出来的图片一般具备比较好的构图,而如果从他们的图片中随机抠出一块,那抠出的图片大概率就毁了。也就是说,原图在构图方面的分数应该高于抠出来的图片。而这种比较的方式,可以很方便地用 Siamese Network 和 hinge loss 实现。另外,这篇论文另一个讨人喜欢的地方在于,它几乎不需要标注数据,只需要在网上爬取很多专业图片,再随机抠图就可以快速构造大量训练样本,因此成本近乎为零,即使精度不高也可以接受。
当然,这篇论文的训练方式只能让网络知道哪种图片的构图好,而无法自动从原图中抠出构图好的图块,因此,在抠图方面,采用的是滑动窗口的策略,并根据网络输出的分数决定哪个窗口最好。
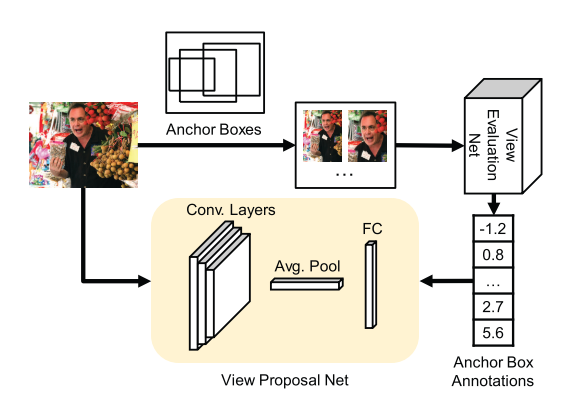
2. Good View Hunting: Learning Photo Composition from Dense View Pairs (CVPR 2018)

上一篇论文虽然方法简单,但由于训练数据太粗糙,所以效果不可能很好。为此,这篇论文的作者自己制作了一个数据集 CPC。这个数据集中的数据也是采用一对图片 (准确的说,是从图片里抠出的 patch) 进行比较 (rank) 的形式标注的 (实际标注步骤分两步,高效合理,值得借鉴),整个数据集总共包含一百多万对图片的标注。
在抠图方面,上一篇论文采用的是滑动窗口这种传统的方法,但这种暴力搜索的方法耗时耗力。受近几年很多物体检测方法的启发,作者采用了 MultiBox 的思路来让网络快速搜索出构图分数更高的窗口。在物体检测中,网络是根据 bounding box 训练的,但在抠图任务里,bounding box 的引导作用并不大。换句话说,两个位置大小相差不大的窗口,其构图分数可能相差很大,但两个相差很大的窗口,却可能有着类似的分数。而且,我们已有的标注数据就只有上面提到的 ranking 数据。
最容易想到的训练方式,就是像上一篇论文一样,直接用 ranking 数据训练网络,再对一个个窗口做判断,不过这样一来这篇论文就没意义了。为了能结合物体检测的优势,作者采用了知识蒸馏的方法,先用 ranking 数据训练一个评分网络 (VEN),再用这个网络训练一个窗口区域选择网络 (VPN)。通过这种巧妙的方法,可以得到一个既能快速抽取窗口的、又能比较准确地给出构图分数的网络。在训练过程中,作者采用了一个跟 ranking 相关的损失函数 MPSE(Mean Pairwise Square Error),也很值得借鉴。
如果有一天,计算机可以在你拍照的时候告诉你哪个角度构图最好,那就是一个成熟的构图了。
美学评价
要是有一种技术,可以告诉我们一副图像拍的如何就好了。随着计算机美学和看图说话技术的发展,这项技术或许将出现在我们日常生活中。
1. Aesthetic Critiques Generation for Photos (ICCV 2017)
开启美学评价这项工作 (坑) 的是台湾的学者。这篇文章顾名思义,就是让机器生成一些跟图片美学相关的评价。作为第一个吃螃蟹的人,如何定义问题是关键的一步。当我们在评价一张图片的时候,我们一般在想什么。大多数情况下,无非是图片的构图好不好,色彩饱和度够不够,主体突不突出等等。遵循这个思路,作者把原问题分解了一下,他们选定几个维度 (比如饱和度、色彩光照等),让机器只针对这几个角度,分别进行评价。这样一来,这个任务跟一般的 image caption 任务就比较类似了。一般的 image caption 任务通常是描述图片中的物体在做什么事情,而本文的任务是描述图像中的某些属性 (饱和度等) 效果怎么样 (好/差)。
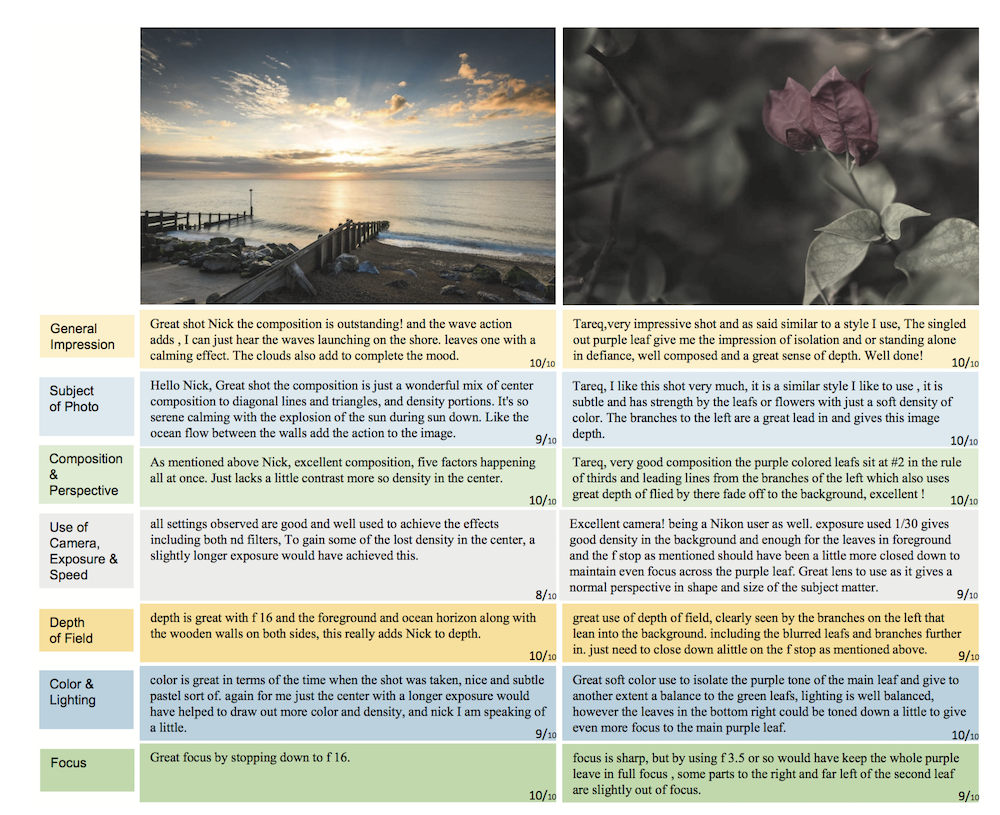
有了基本思路后,作者在一个图像评论网站上爬取了图片和评论数据,并制作了该任务首个数据集 PCCD,这个数据集中包含 4000+ 图片,每张图片对应 7 句描述 (分别对应 7 个维度,包括总体印象、光照、饱和度等),同时每张图片会有 7 个打分 (也分别对应这 7 个维度)。除此以外,论文还定义了一个比较适合该任务的评价标准 SPICE,感兴趣的读者可以参考原论文。下图是数据集中的两个样本:
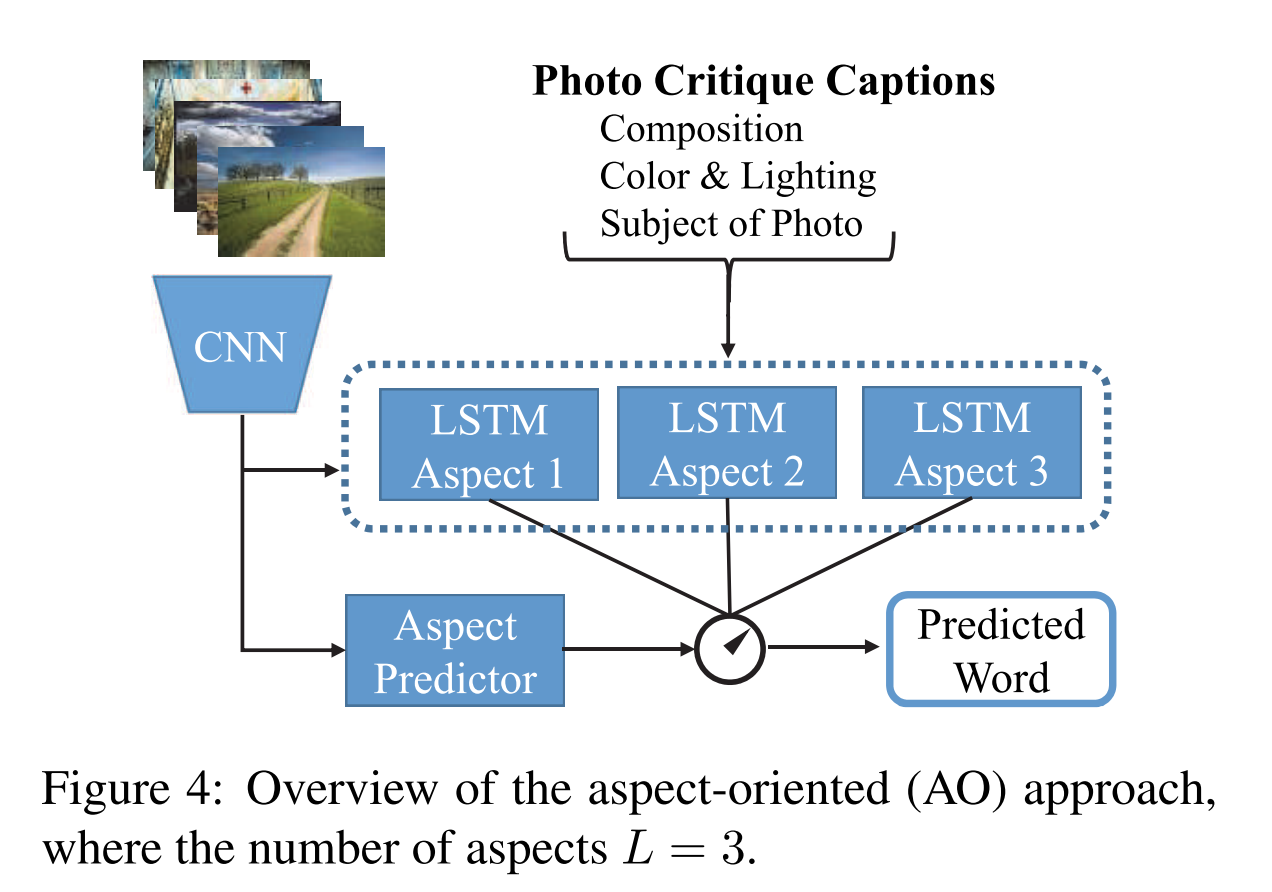
在算法框架上,论文基本是参照了 image caption 中一些比较成功的模型。最简单也最容易想到的方法就是直接套用 CNN-LSTM 框架,并针对美学任务本身做一些定制操作 (比如把 CNN 换成针对美学评分的 CNN)。当然实际操作时会遇到很多问题,论文遇到的最大的问题就是生成的评价很单一 (比如总是生成针对饱和度的评价),这一点可能跟数据集中的数据分布有关。另一个思路则是专门针对不同的维度训练不同 CNN-LSTM 模型 (AO, aspect-oriented),如下图所示:
先用一个 CNN 预测图像的美学类型 (饱和度或者构图等),再把 CNN 抽取的特征输入 LSTM 生成 caption,训练的时候可以根据 CNN 预测的美学类型,用对应类型的评价作为 ground truth 来训练模型。这种方法本身应该是有效的,但却过于繁琐,所以论文又给出了另一种方法,将这些不同维度的模型融合成一个统一的框架 (AF, aspect-fusion),见下图:
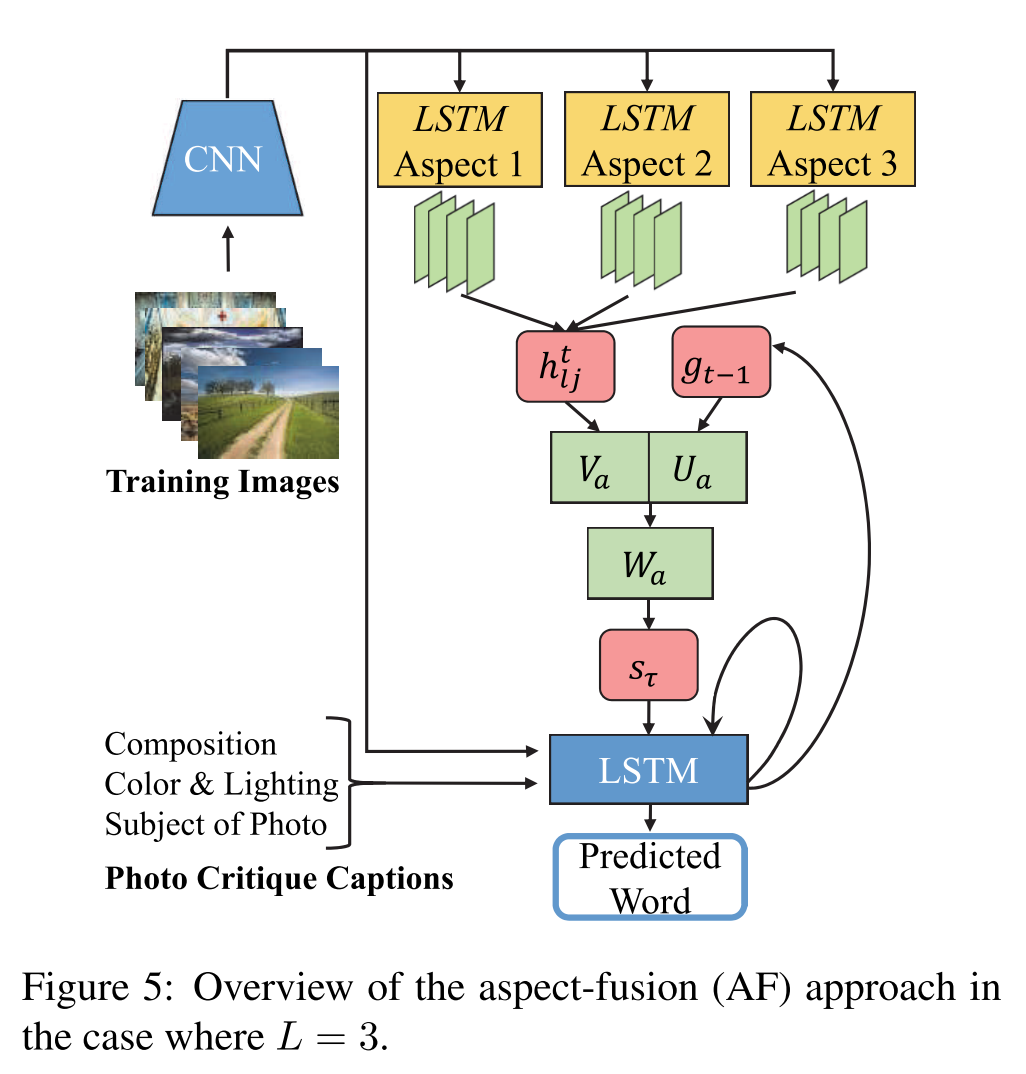
它的思路是把训练好的单维度模型 (AO) 提取到的隐变量 (hidden state) 抽取出来,然后用 Attention 机制一顿操作后生成新的 LSTM 的隐变量 (hidden state),
下面是部分实验结果:

从生成的句子来看,还有鼻子有眼的,而且基本跟图片内容很 match。当然也不乏失败的结果:

总之,作为一个新挖的坑,这篇论文给了一个很好的研究思路,也给之后的研究提供了足够的提升空间。
2. Aesthetic Attributes Assessment of Images (ACM MM 2019)
上一篇论文虽然挖好了坑,但挖的不够深。这篇论文从两个角度进一步完善该任务:1) 扩充一个更大的数据集;2) 让网络可以同时输出多个维度属性的描述 (上一篇论文会根据 CNN 预测的最大概率的属性来生成描述,因此每幅图只会生成一句描述)。
首先,要构建一个更大的数据集。PCCD 中只包含了 4000+ 的图片,数量上比起 AVA 等经典美学数据集 (250000+) 来说,实在太小。所以这篇论文又从 DPChallenge 上面爬取了三十万图片以及相应的描述,然后从 PCCD 中选取了几个属性以及关键词来清洗和整理这些数据,最后得到 150000+ 条数据。下面是该任务几个数据集的对比:
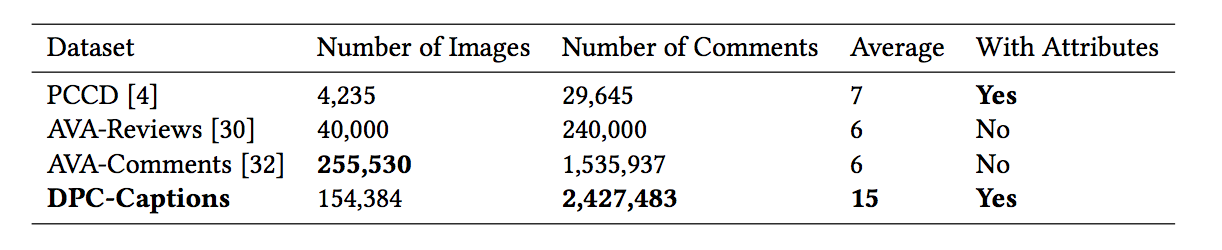
这个数据集和 PCCD 相比,除了规模更大之外,另一个区别在于每张图片的每个属性不在提供评分,因为图片数量太多了,想给每个属性一一评分几乎不可能。不过好在每条评论都会对应唯一的属性,这样多少也算是一种弱标注吧。
有了这个数据后,就可以跑更大更浮夸的模型了。给个模型框架图感受一下:
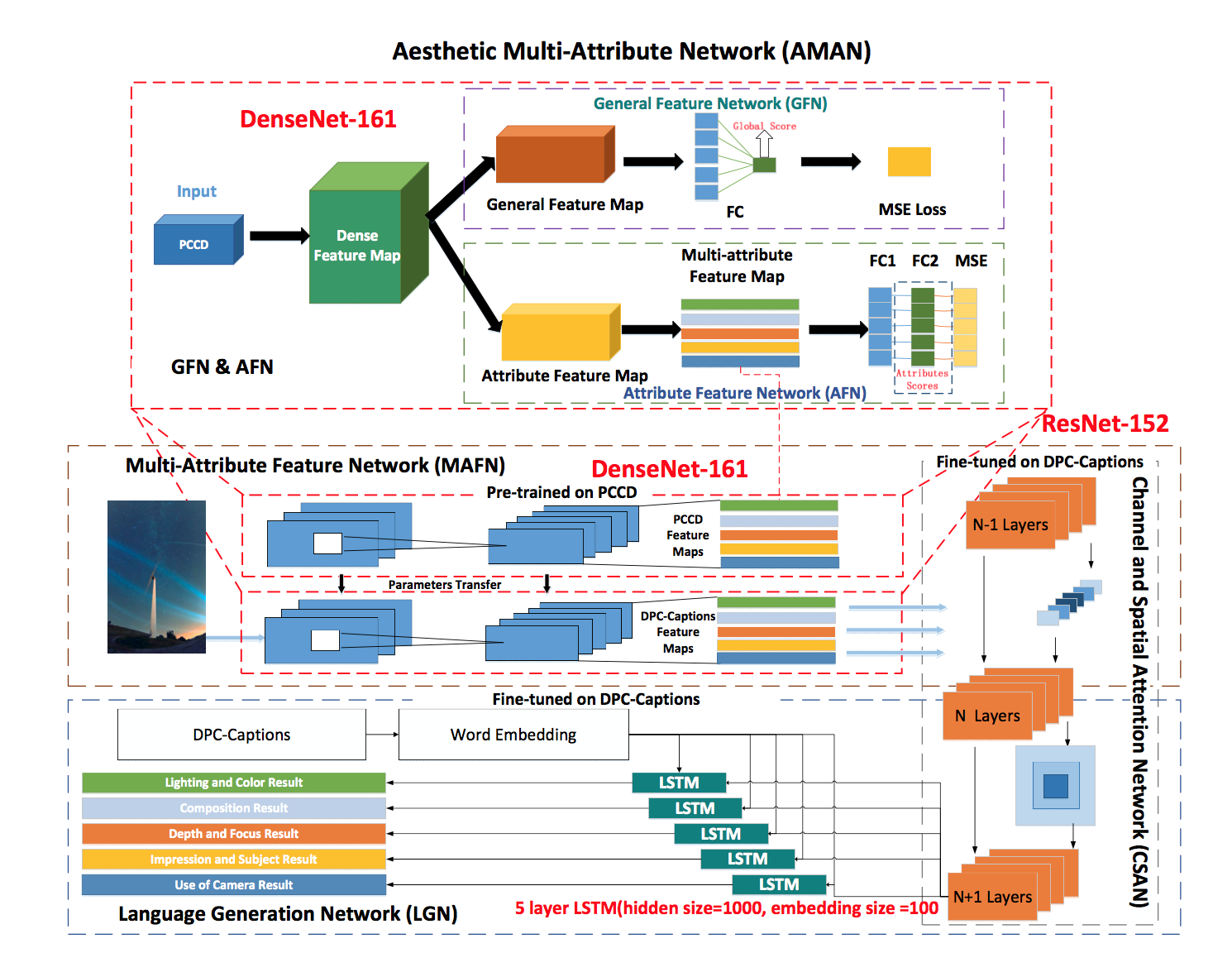
作者是在 PCCD 上先根据每个属性的评分预训练一番,再在自己的数据上 finetune 的。但由于两个数据集规模相差巨大,我很怀疑这种预训练的效果。从算法框架来看,依然是经典的 CNN+LSTM+Attention 的组合。
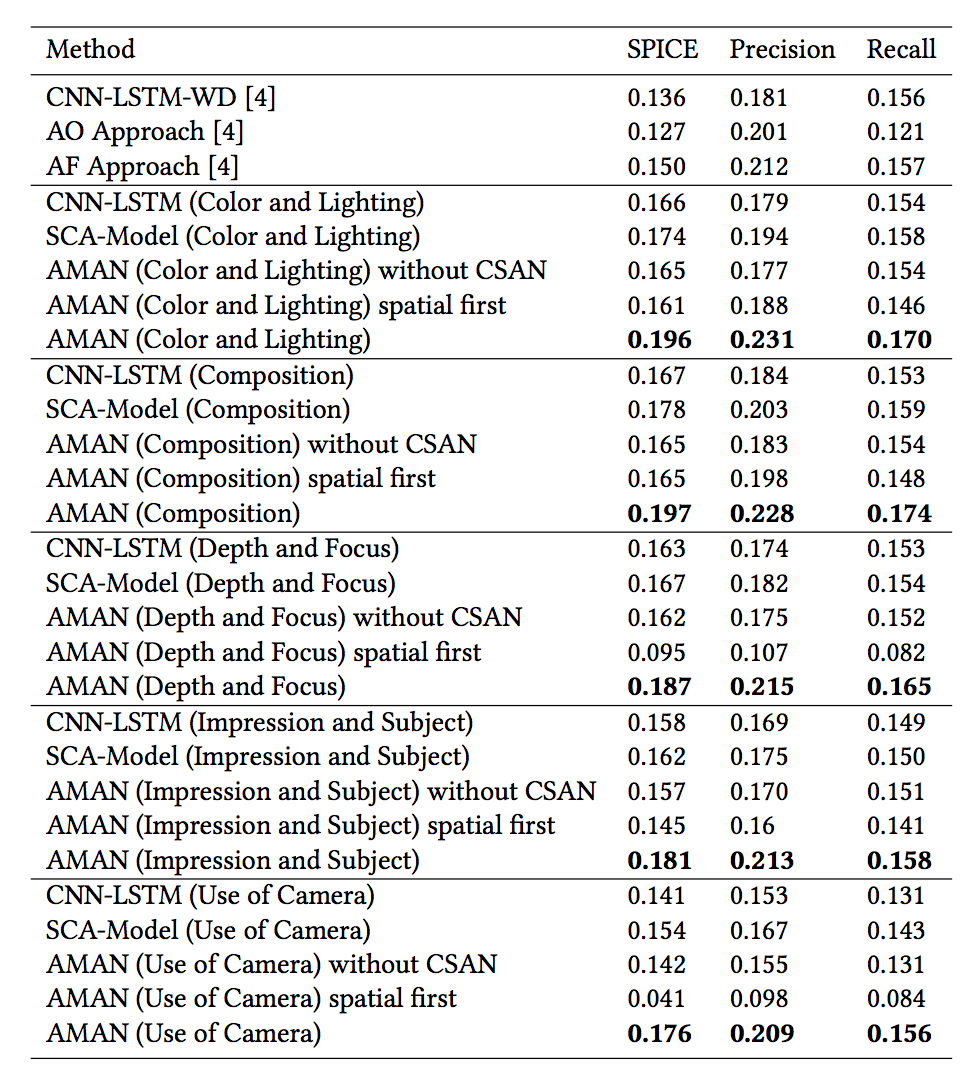
下面是论文模型在 PCCD 上的实验结果,从结果来看,论文在 SPICE 指标上的性能都要高出一截。当然啦,论文的模型是在大数据集上训练的,所以跟前一篇论文的结果 (AO, AF) 没有可比性,但大数量对模型的效果应该有很大的帮助。
由于这个课题有一定应用前景,跟自然语言处理的联系也比较紧密,算是一个跨模态任务,可以挖的点很多,可以预见,未来会有更多的工作填这个坑。
总结
总的来说,计算机美学由于主观性非常强,因此难点在于如何把问题定义好。比如美学评价里面,如何对图片进行评价就是最根本的问题,而自动裁剪任务中,又需要研究怎样裁剪得到的图片最好。根据定义好的问题,收集数据集,再建立相关的模型进行学习。这个任务另一个难点在于建模本身非常的困难,因为我们不清楚美学本身的数学模型长什么样子,因此也就很难在模型中加入一些显性的知识作为引导。熟悉这块工作的读者也会发现,在机器学习尤其是深度学习的背景下,几乎所有计算机美学的模型都是针对数据集进行构建的,而这些模型本身是否真的在学习鉴赏图片,nobody knows.
另外,看了这么多论文后,也可以对各类研究工作归个类。打个比方就是:一流的工作挖坑,二流的工作用推土机填坑,三流的工作修推土机。
参考
PS: 之后的文章更多的会发布在公众号上,欢迎有兴趣的读者关注我的个人公众号:AI小男孩,扫描下方的二维码即可关注