曾经,为了处理一些序列相关的数据,我稍微了解了一点递归网络 (RNN) 的东西。由于当时只会 tensorflow,就从官网上找了一些 tensorflow 相关的 demo,中间陆陆续续折腾了两个多星期,才对 squence to sequence,sequence classification 这些常见的模型和代码有了一些肤浅的认识。虽然只是多了时间这个维度,但 RNN 相关的东西,不仅是模型搭建上,在数据处理方面的繁琐程度也比 CNN 要高一个 level。另外,我也是从那个时候开始对 tensorflow 产生抵触心理,在 tf 中,你知道 RNN 有几种写法吗?你知道 dynamic_rnn 和 static_rnn 有什么区别吗?各种纷繁复杂的概念无疑加大了初学者的门槛。后来我花了一两天的时间转向 pytorch 后,感觉整个世界瞬间清净了 (当然了,学 tf 的好处就是转其他框架的时候非常快,但从其他框架转 tf 却可能生不如死)。pytorch 在模型搭建和数据处理方面都非常好上手,比起 tf 而言,代码写起来更加整洁干净,而且开发人员更容易理解代码的运作流程。不过,在 RNN 这个问题上,新手还是容易犯嘀咕。趁着这一周刚刚摸清了 pytorch 搭建 RNN 的套路,我准备记录一下用 pytorch 搭建 RNN 的基本流程,以及数据处理方面要注意的问题,希望后来的同学们少流点血泪…
至于 tf 怎么写 RNN,之后有闲再补上 (我现在是真的不想回去碰那颗烫手的山芋😩)
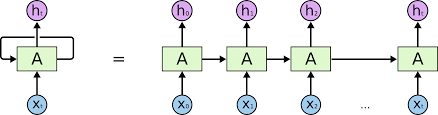
什么是 RNN
虽然说我们用的是 API,但对于 RNN 是什么东西还是得了解一下吧。对于从没接触过 RNN 的小白来说,karpathy 这篇家喻户晓的文章是一定要读一下的,如果想更加形象地了解它的工作机制,可以搜一些李宏毅的深度学习教程。
RNN 其实也是一个普通的神经网络,只不过多了一个 hidden state 来保存历史信息。跟一般网络不同的是,RNN 网络的输入数据的维度通常是 \([batch\_size \times seq\_len \times input\_size ]\),它多了一个序列长度 \(seq\_len\)。在前向过程中,我们会把样本 \(t\) 个时间序列的信息不断输入同一个网络 (见上图),因为是重复地使用同一个网络,所以称为递归网络。
关于 RNN,你只需要记住一个公式:\(h_t = \tanh(w_{ih} x_t + b_{ih} + w_{hh} h_{(t-1)} + b_{hh})\)。这也是 pytorch 官方文档中给出的最原始的 RNN 公式,其中 \(w_{*}\) 表示 weight,\(b_{*}\) 表示 bias,\(x_t\) 是输入,\(h_t\) 是隐藏状态。回忆一下,普通的神经网络只有 \(w_{ih} x_t + b_{ih}\) 这一部分,而 RNN 无非就是多加了一个隐藏状态的信息 \(w_{hh} h_{(t-1)} + b_{hh}\) 而已。
普通网络都是一次前向传播就得到结果,而 RNN 因为多了 sequence 这个维度,所以需要跑 n 次前向。我们用 numpy 的写法把 RNN 的工作流程总结一下,就得到了如下代码 (部分抄自 karpathy 的文章):
1 | # 这里要啰嗦一句,karpathy在RNN的前向中还计算了一个输出向量output vector, |
过来人血泪教训:一定要看懂上面的代码再往下读呀。
pytorch 中的 RNN
好了,现在可以进入本文正题了。我们分数据处理和模型搭建两部分来介绍。
数据处理
pytorch 的数据读取框架方便易用,比 tf 的 Dataset 更有亲和力。另外,tf 的数据队列底层是用 C++ 的多线程实现的,因此数据读取和预处理都要使用 tf 内部提供的 API,否则就失去多线程的能力,这一点实在是令人脑壳疼。再者,过来人血泪教训,tf 1.4 版本的 Dataset api 有线程死锁的bug,谁用谁知道😈。而 pytorch 基于多进程的数据读取机制,避免 python GIL 的问题,同时代码编写上更加灵活,可以随意使用 opencv、PIL 进行处理,爽到飞起。
pytorch 的数据读取队列主要靠 torch.utils.data.Dataset 和 torch.utils.data.DataLoader 实现,具体用法这里略过,主要讲一下在 RNN 模型中,数据处理有哪些需要注意的地方。
在一般的数据读取任务中,我们只需要在 Dataset 的 __getitem__ 方法中返回一个样本即可,pytorch 会自动帮我们把一个 batch 的样本组装起来,因此,在 RNN 相关的任务中,__getitem__ 通常返回的是一个维度为 \([seq\_len \times input\_size]\) 的数据。这时,我们会遇到第一个问题,那就是不同样本的 \(seq\_len\) 是否相同。如果相同的话,那之后就省事太多了,但如果不同,这个地方就会成为初学者第一道坎。因此,下面就针对 \(seq\_len\) 不同的情况介绍一下通用的处理方法。
首先需要明确的是,如果 \(seq\_len\) 不同,那么 pytorch 在组装 batch 的时候会首先报错,因为一个 batch 必须是一个 n-dimensional 的 tensor,\(seq\_len\) 不同的话,证明有一个维度的长度是不固定的,那就没法组装成一个方方正正的 tensor 了。因此,在数据预处理时,需要记录下每个样本的 \(seq\_len\),然后统计出一个均值或者最大值,之后,每次取数据的时候,都必须把数据的 \(seq\_len\) 填充 (补0) 或者裁剪到这个固定的长度,而且要记得把该样本真实的 \(seq\_len\) 也一起取出来 (后面有大用)。例如下面的代码:
1 | def __getitem__(self, idx): |
这样,你从外部拿到的 batch 数据就是一个 \([batch\_size \times max\_seq\_len \times input\_size]\) 的 tensor。
模型搭建
RNN
拿到数据后,下面就要正式用 pytorch 的 RNN 了。从我最开始写的那段 RNN 的代码也能看出,RNN 其实就是在一个循环中不断的 forward 而已。但直接循环调用其实是非常低效的,pytoch 内部会用 CUDA 的函数来加速这里的操作,对于直接调 API 的我们来说,只需要知道 RNN 返回给我们的是什么即可。让我们翻开官方文档:
class torch.nn.RNN(*args, **kwargs)
Parameters: input_size, hidden_size, num_layers, …
Inputs: input, h_0
- input of shape (seq_len, batch, input_size)
- h_0 of shape (num_layers * num_directions, batch, hidden_size)
Outputs: output, h_n
- output of shape (seq_len, batch, num_directions * hidden_size)
- h_n (num_layers * num_directions, batch, hidden_size)
这里我只摘录初始化参数以及输入输出的 shape,记住这些信息就够了,下面会讲具体怎么用。注意,shape 里面有一个 num_directions,这玩意表示这个 RNN 是单向还是双向的,简单起见,我们这里默认都是单向的 (即num_directions=1)。
现在借用这篇文章中的例子做讲解。
首先,我们初始化一个RNN:
1 | batch_size = 2 |
然后,假设我们的输入数据是这样子的:
1 | x = torch.FloatTensor([[1, 0, 0], [1, 2, 3]]).resize_(2, 3, 1) |
可以看到输入数据的维度是 \([2 \times 3 \times 1]\),也就是 \(batch\_size=2\),\(seq\_len=3\),\(input\_size=1\)。但要注意一点,第一个样本的 \(seq\_len\) 的有效长度其实是 1,后面两位都补了 0。那么,在实际计算的时候,第一个样本其实只要跑 1 遍 forward 即可,而第二个样本才需要跑 3 遍 forward。
pack_padded_sequence
那如何让RNN知道不同样本的序列长度不一样呢?幸运的是,pytorch 已经提供了很好的接口来处理这种情况了。如果输入样本的 \(seq\_len\) 长度不一样,我们需要把输入的每个样本重新打包 (pack)。具体来讲,pytorch 提供了 torch.nn.utils.rnn.pack_padded_sequence 接口,它会帮我们把输入转为一个 PackedSequence 对象,而后者就包含了每个样本的 \(seq\_len\) 信息。pack_padded_sequence最主要的输入是输入数据以及每个样本的 \(seq\_len\) 组成的 list。需要注意的是,我们必须把输入数据按照 \(seq\_len\) 从大到小排列后才能送入 pack_padded_sequence。我们继续之前的例子:
1 | # 对seq_len进行排序 |
理解这里的 PackedSequence 是关键。
前面说到,RNN 其实就是在循环地 forward。在上面这个例子中,它每次 forward 的数据是这样的:
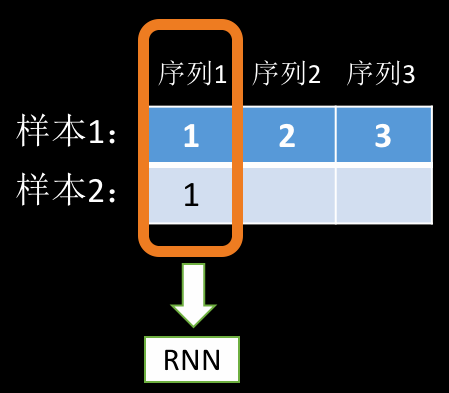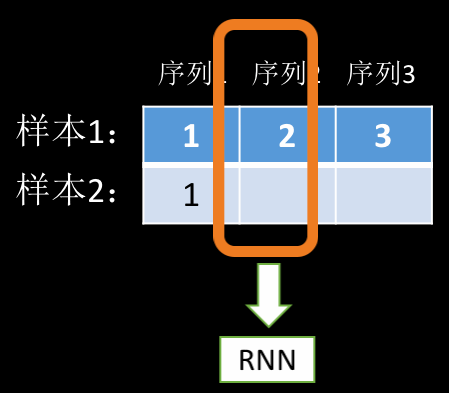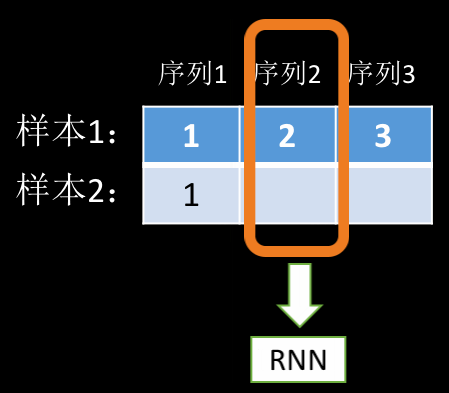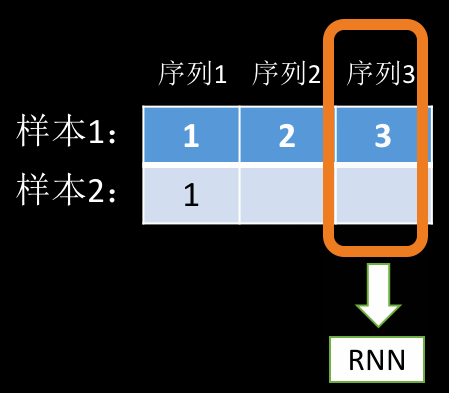
第一个序列中,由于两个样本都有数据,所以可以看作是 \(batch\_size=2\) 的输入,后面两个序列只有第一个样本有数据,所以可以看作是 \(batch\_size=1\) 的输入。因此,我们其实可以把这三个序列的数据分解为三个 batch 样本,只不过 batch 的大小分别为 2,1,1。到这里你应该清楚 PackedSequence 里的 data 和 batch_size 是什么东西了吧,其实就是把我们的输入数据重新整理打包成 data,同时根据我们传入的 seq list 计算 batch_size,然后,RNN 会根据 batch_size 从打包好的 data 里面取数据,然后一遍遍的执行 forward 函数。
理解这一步后,主要难点就解决了。
RNN的输出
从文档中可以看出,RNN 输出两个东西:output 和 h_n。其中,h_n 是跑完整个时间序列后 hidden state 的数值,其中 num_layers 表示这个 RNN 有多少层神经元,比如,一个由两层 500 维的全连接层组成的 RNN,其 num_layers 就是 2。但 output 又是什么呢?之前不是说过原始的 RNN 只输出 hidden state 吗,为什么这里又会有一个 output?其实,这个 output 并不是我们理解的网络最后的 output vector,而是每次 forward 后计算得到的 hidden state。毕竟 h_n 只保留了最后一步的 hidden state,但中间的 hidden state 也有可能会参与计算,所以 pytorch 把中间每一步输出的 hidden state 都放到 output 中(当然,只保留了 hidden state 最后一层的输出),因此,你可以发现这个 output 的维度是 (seq_len, batch, num_directions * hidden_size)。
不过,如果你之前用 pack_padded_sequence 打包过数据,那么为了保证输入输出的一致性,pytorch 也会把 output 打包成一个 PackedSequence 对象,我们将上面例子的数据输入 RNN ,看看输出是什么样子的:
1 | # initialize |
输出的 PackedSequence 中包含两部分,其中 data 才是我们要的 output。但这个 output 的 shape 并不是 (seq_len, batch, num_directions * hidden_size),因为 pytorch 已经把输入数据中那些填充的 0 去掉了,因此输出来的数据对应的是真实的序列长度。我们要把它重新填充回一个方方正正的 tensor 才方便处理,这里会用到另一个相反的操作函数 torch.nn.utils.pad_packed_sequence:
1 | # unpack |
现在,这个 output 的 shape 就是一个标准形式了。
不过我一般更习惯 batch_size 作为第一个维度,所以可以稍微调整下:
1 | # seq_len x batch_size x hidden_size --> batch_size x seq_len x hidden_size |
现在,输入输出就一一对应了。之后,你可以从 output 中取出你需要的 hidden state,然后接个全连接层之类的,得到真正意义上的 output vector。取出 hidden state 一般会用到 torch.gather 函数,比如,如果我想取出最后一个时间序列的 hidden state,可以这样写 (这段代码就不多解释了,请查一下 torch.gather 的用法,自行体会):
1 | # bz来自上面的例子, bz=tensor([ 3, 1]) |
对了,最后要注意一点,因为 pack_padded_sequence 把输入数据按照 \(seq\_len\) 从大到小重新排序了,所以后面在计算 loss 的时候,要么把 output 的顺序重新调整回去,要么把 target 数据的顺序也按照新的 \(seq\_len\) 重新排序。当 target 是 label 时,调整起来还算方便,但如果 target 也是序列类型的数据,可能会多点体力活,可以参考这篇文章进行调整。