最近想做一个识别验证码的程序。目标其实很简单,就是识别出某网站验证码的字母和数字。

这种类型的验证码已经被做烂了,相应的破解程序也很多。但我只是想学习消遣一下。
我已经通过爬虫收集了某网站的大量验证码图片,并通过图像处理的方法把字母和数字分割出来(好在这类验证码比较简单,切割工作相对容易)。之后,便是要对这些图片进行标记并训练。我总共爬了 20000 张,每张上面有四个数字或字母,相当于要对 80000 张图片做标记分类。嗯,这很有趣!
需求分析
通过对原图进行处理分割后,我已经得到如下的图片数据(图片尺寸 32 * 32,除了灰度图,最好保留对应的原图):

现在,要将这些图片分门别类。数字和字母,最多可以组合出 10 + 26 = 36 类,但仔细观察数据后,我发现有很多数字和字母压根没出现。通过粗略地扫描一下数据,我统计出这个网站的验证码总共只使用了 23 类数字和字母。于是,我按照如下规则对图片做了分类:
1 | image_tag = {0: '3', 1: '5', 2: '6', 3: '7', 4: '8', 5: 'a', 6: 'c', 7: 'e', 8: 'f', 9: 'g', 10: 'h', 11: 'j', 12: 'k', 13: 'm', 14: 'n', 15: 'p', 16: 'r', 17: 's', 18: 't', 19: 'v', 20: 'w', 21: 'x', 22: 'y'} |
将出现的数字和字母分为 23 类。然后,接下来的目标,就是把图片分到如下 23 个文件夹中:

实现思路
很多人都觉得标数据这种事情很没技术含量,纯属「dirty work」。如果你只是单纯地用肉眼把一张张图片分到这些目录里面,当然显得很「笨拙」。而且,仔细想想,80000 张图片的分类,(一个人)几乎是不可能人工完成的。我们要用优雅的方法来归类。
这个优雅的方法其实也很简单。分以下几步进行:
- 先人工挑出几个或十几个样本,训练一个分类器出来,这个分类器准确率会很低,但不要紧;
- 再从原图片中,选出几十上百张,用刚才的分类器对它们进行分类。由于分类器精度有限,需要从分类后的结果中挑出分错的样本,然后人工将它们分到正确的目录(这个工作比你自己去对上百张图片做分类真的要轻松好多);
- 用已经分好类的数据继续训练一个新的分类器,重复第 2 步直到数据都分类完(随着分类器精度提高,可以逐步增加待分类图片的数量);
这个方法虽然还是需要不少人工辅助,但总体来说,比人工手动分类的效率实在高太多了。
具体实现
人工选取小样本
要训练分类器,挑选样本是必须的,我从分割的图片中,随机挑出一两百张,将它们分类到相应的目录内:
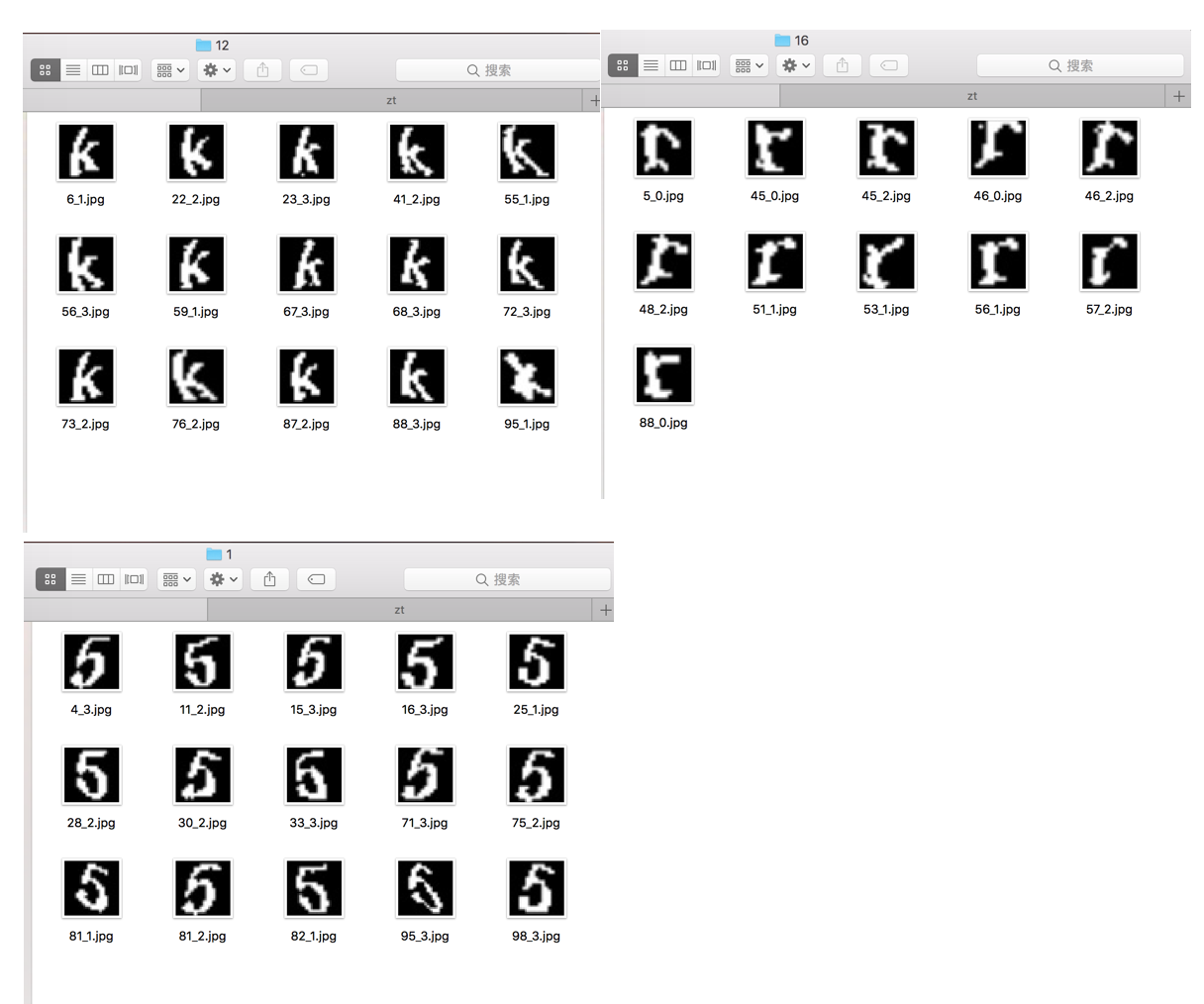
然后,我需要一个函数来读取这些文件夹的数据,方便之后继续训练。
1 | '''读取图片数据文件,转换成numpy格式,并保存''' |
这个函数的主要工作是循环每一个目录文件夹里的文件,将它们依次读入,变成矩阵形式方便处理,并通过 Pickle 保存成文件。
这里主要用了其他几个函数的功能:
1
load_letter(image_folder) # 读取一个tag文件夹里的推按文件,并返回所有图片数据的矩阵
1
merge_datasets(train_image_data, train_image_label) # 将所有类别的图片数据合并成一个大的矩阵样本数据
1
randomize(train_dataset, train_label) # 打乱训练数据
<br>
下面放点关键函数的代码。
load_letter() 函数代码如下,对图片的读取用了 opencv:
1 | '''读取同种类别的图片转换成numpy数组''' |
代码比较简单,就不多解释了。
<br>
merge_datasets() 函数代码:
1 | def merge_datasets(train_image_data, train_image_label): |
<br>
训练分类器
好了,准备好数据,我们需要训练一个分类器。简单起见,这里选择用 SVM,并选用 sklearn 函数库。
其实,可以直接把图片矩阵转换成一个向量进行训练(32 * 32 —> 1 * 1024),但我们拥有的数据量太少,这样效果较差。所以,我们先提取图片的 HOG 特征再进行训练:
1 | bin_n = 16 # Number of bins |
这个函数代码摘自 opencv3 的文档,想了解代码,请自行去官网阅读文档。
有了特征之后,我们可以正式用 SVM 进行训练了:
1 | def train_svm(train_datasets, train_labels): |
这个函数代码一样很简单,如果看不懂,证明你需要熟悉 numpy 和 sklearn 函数库的用法。
然后,我们需要选取图片进行预测分类。可以人工挑出个几百上千张,放在一个预测目录内。同时再开一个目录文件夹如下:
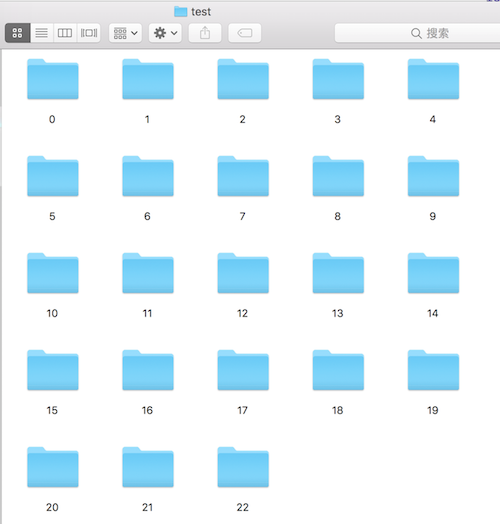
这个 test 文件夹和先前人工分类的文件夹要分开,因为之后还要人工对这里面的图片除杂。最后,我们遍历预测目录内的图片,用 SVM 做预测,并将图片放到预测结果对应的文件夹里。
测试函数代码如下:
1 | def test_image(image_folder, result_folder, model): |
<b>
做完这一步,我们最关键,同时也是最优雅的一步就完成了。之后,SVM 也帮不了你了。你需要依次打开每个文件夹,看看里面的图片有没有分错的,然后人工矫正它们,最后把它们归类到我们一开始挑选样本分好类的文件夹里,后者这个文件夹的数据表示已经分类好的。
如果运气好的,这个初步训练好的 SVM 已经稍微有点「聪明」了。看看我得到的分类结果:
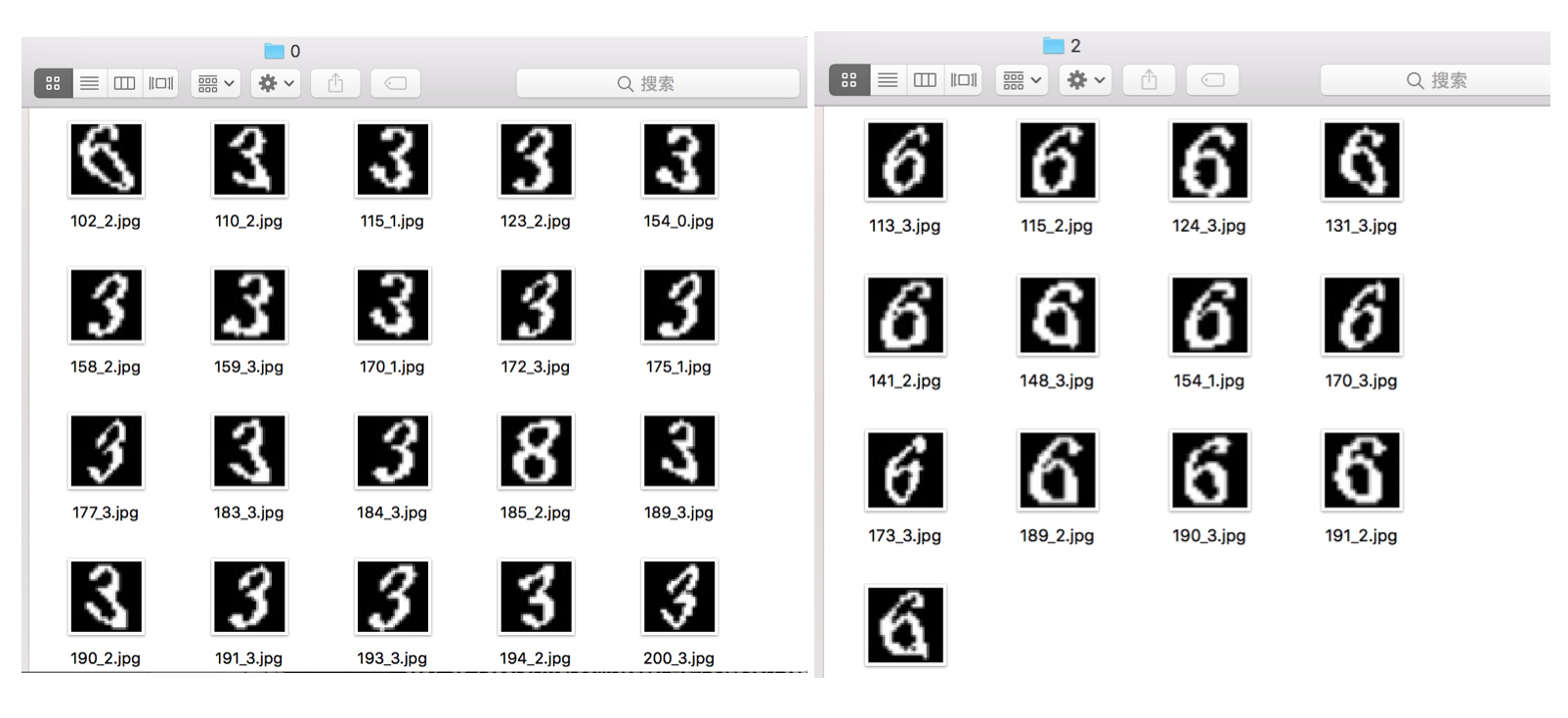
这个准确率我已经很欣慰了,基本上人工挑出几张分错的,剩下的都是同一类了。
当然,肯定有分的不好的情况:
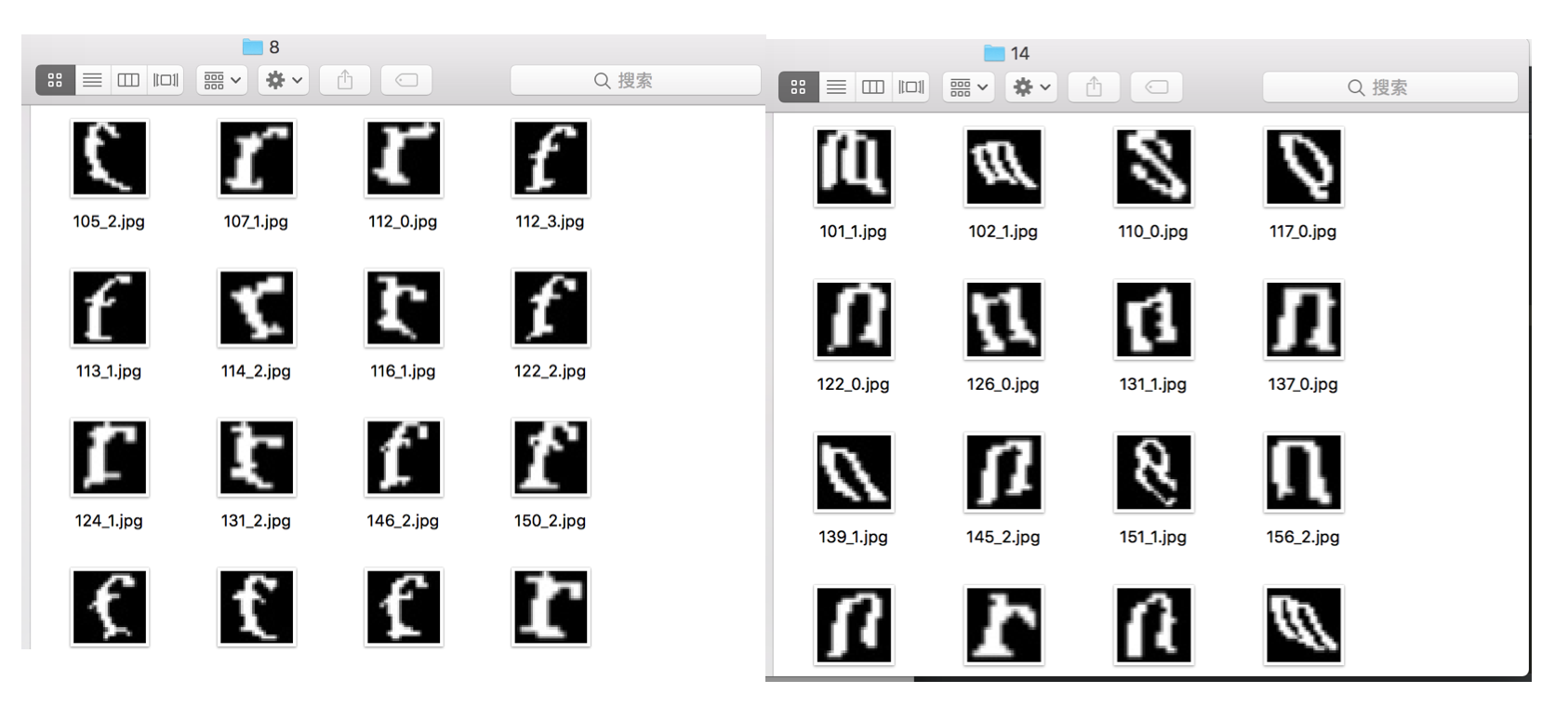
对于这种,就是发挥你眼力的时候了。基本上,之后所有的工作都是在这一堆类似的图片里面找不同。当然,你要相信这种情况会越来越少,因为随着训练样本逐渐增多,SVM 的训练效果会越来越好。如果越到后面效果越差,程序员,请你不要怀疑,一定是你的代码出问题了。
<br>
接下来我给出整个程序的主体部分:
1 | if __name__ == '__main__': |
main 函数就是上面几个函数的结合。之后,我们就是不断地 run 一遍代码,人工除杂精分类,再 run 一遍代码,再人工……循环往复直到数据分类完为止。
总结
这个方法可以节省你大量的体力活动,有助于提高逼格。虽然如此,这 80000 个样本我还是生生花了一天半时间才分完,工作量还是稍微超出预期。如果有小伙伴有逼格更高,更能提高生产效率的方法,望不吝赐教!