关于决策树,想必大部分人都已经耳熟能详了,这是一种用来预测行为的树状分叉结构。本文主要想总结一下最常用的决策树生成算法:ID3,C4.5 以及 CART。
构造的原则
熟悉决策树的你一定记得,决策树每个非叶子结点对应的其实是一个属性。比方说,想判断一个男生是不是 gay,我们首先需要判断他的性别是不是男的,是的话继续判断他的性取向,之后继续判断他的其他行为……这里的「性别」,「性取向」就是属性,而决策树的生成其实是依次挑选这些属性组成自己的节点,到最终可以明确得出结论的时候(也就是叶子结点),整棵树便生成了。所以,我们的目标就是按照某种方法依次挑选出这些属性。
我们挑选的原则是:每次选出这个属性后,可以最大限度地减小分类的可能性。回到 gay 这个问题,如果摆在我们眼前的属性有:「性取向」,「是否喜欢日漫」,「是否长发披肩」,那么,选择「性取向」这个属性,对我们之后的判断,帮助无疑是最大的。因为得知「性取向」之后,基本也就得到结论了。所以,对这个例子而言,「性取向」是我们优先挑选的属性。
那么,我们如何衡量这种帮助的大小呢?请往下看👇。
ID3 算法
ID3 算法归根到底就是提出一种合理的选择属性的方法。
(注意,决策树是一种知识学习算法,只有从众多样本中才能得出哪个属性最好,所以,构造决策树的前提是有大量的样本可供学习)
下面,为了方便讲解,我们需要引入信息学中「熵」的概念。
熵(entropy)
第一次接触熵的概念是在学高中化学的时候,课本告诉我们:一堆整齐有序的分子,最终都会演变成一个混乱复杂的群体,也就是,这个系统的熵值会逐渐变大。因此,简单整齐的系统,熵越小,越混乱的系统,熵越大。接下来,让我们回顾一下分子的布朗运动……
开个玩笑啦🤗。
同化学里的熵一样,信息学的熵也有类似的作用。在信息学中,如果熵越大,证明掌握的信息越少,事情越不确定。看到这里,你有没有觉得,熵的定义和我们前面提出的挑选属性的原则有点类似。是的,ID3 的精髓也就是在这,它通过计算属性的熵,来得出一个属性对事情的确定性能产生多大的影响,从而选出最好的属性。
那么熵该如何度量呢?
著名的信息论创始人「香农」提出一个度量熵的方法:假设有一堆样本 D,那么 D 的熵可以这样计算: \[ H(D)=-\sum_{i=1}^{m}{p_ilog_2(p_i)} \] 其中,\(p_i\) 表示第 i 个类别在整个样本中出现的概率。 举个例子吧。假设我们投掷 10 枚硬币,其中,5 枚正面朝上,5 枚正面朝下,那么我们总共得到 10 个样本,这堆样本的熵为:
\(H(D)=-(\frac{5}{10}log_2{\frac{5}{10}} + \frac{5}{10}log_2{\frac{5}{10}})=1\)
反之,如果只有 1 枚硬币正面朝上,9 枚硬币正面朝下,那么熵为:
\(H(D)=-(\frac{1}{10}log_2{\frac{1}{10}} + \frac{9}{10}log_2{\frac{9}{10}})=0.469\)
如果全部硬币正面朝上,你应该可以算出来,熵为 0。 举这个例子是想说明:当熵的值越大的时候,事情会更加难以确定,如果你知道 10 次实验中,正面朝上的为 5 次,朝下的也为 5 次,那么下一次哪一面朝上,你是不是很难确定。相反,如果熵的值越小,事情就越明朗。当熵为 0,也就是 10 次都正面朝上的时候,下一次你会不会觉得正面朝上的概率会大很多(请忘掉你的传统思维,我没说这是一枚正常的硬币)。
选择属性
好了,有了熵的概念以及度量方法,下面我们可以正式地走一遍 ID3 的流程了。 同样的,假设我们有一堆数据 D,我们先计算出这堆样本的熵\(H(D)\),接下来,我们要对每个属性对信息的价值进行评估。假设我们挑选出 A 属性,那么,根据 A 属性的类别,我们可以把这堆样本分成几个子样本,每个子样本都对应 A 属性中的一类。我们继续按照熵的定义计算这几个子样本的熵,由于它们的熵是挑选出 A 后剩下的,因此我们定义为: \[ Remainder(A)=\sum_{j=1}^{v}\frac{|D_j|}{|D|}H(D_j) \] 这个公式其实和之前的是一个道理,我们通过 A 将 D 分成几个子集 \(D_j\),这个时候,我们仍然需要计算这堆样本的熵,因此,先分别计算出每个 \(D_j\) 的熵,然后乘以这个 \(D_j\) 样本占所有数据集的比重,最后将全部子集的熵加起来即可。前面说了,这个熵是挑选 A 后剩下的,那么很自然的,我们想知道 A 到底帮助消减了多少熵,于是,我们定义最后一个公式,即信息增益: \[ Gain(A)=H(D)-Remainder(A) \] 之前对熵的说明告诉我们,熵越大,信息越少,反之,信息越多。\(Gain(A)\)其实就是 A 对信息的确定作用,它是我们选出 A 属性后,信息的混乱程度减少的量。 好了,到这里,ID3 的关键部分已经讲完了。其实,每次挑选属性的时候,我们都是计算出所有属性的信息增益,选择最大的作为分裂的属性,将样本分成几个子集,然后,对每个子集,继续选出最好的属性,继续分裂,直到所有样本都属于同一类为止(都是 gay 或者都是正面朝上)
举个例子
下面用的这个例子摘自文末的参考博客算法杂货铺——分类算法之决策树(Decision tree)。 假设我们有以下这堆 SNS 社区的资料,我们想确定一个账号是否是真实。
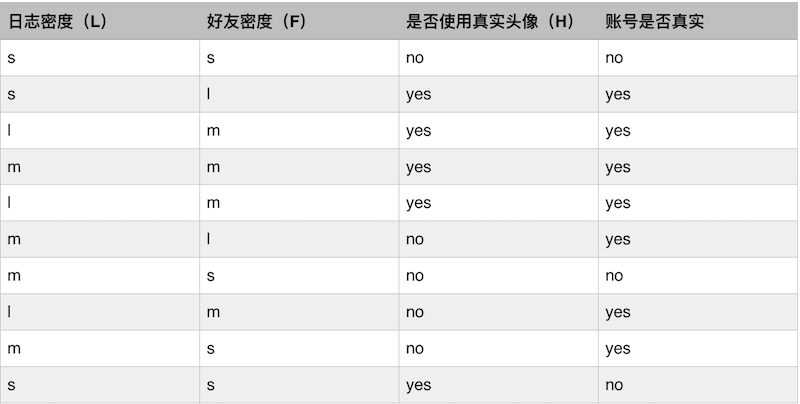
其中,s 、m 和 l 分别表示小、中和大。 我们先计算出这堆样本的熵:
\(H(D)=-(0.7*log_2{0.7}+0.3*log_2{0.3}) = 0.879\)
然后,我们计算每个属性的信息增益:
\[ \begin{align} Remainder(L)=&0.3*(-\frac{0}{3}log_2{0}{3}-\frac{3}{3}log_2{\frac{3}{3}})\\&+0.4*(-\frac{1}{4}log_2\frac{1}{4}-\frac{3}{4}log_2\frac{3}{4})\\&+0.3*(-\frac{1}{3}log_2\frac{1}{3})=0.603 \end{align} \]
\[ Gain(L)=0.879-0.603=0.276 \]
同样的道理:
\[Gain(F)=0.553\]
\[Gain(H)=0.033\]
经过比较,我们发现 F 的增益最高,于是选出 F 作为节点,构造出如下决策树:
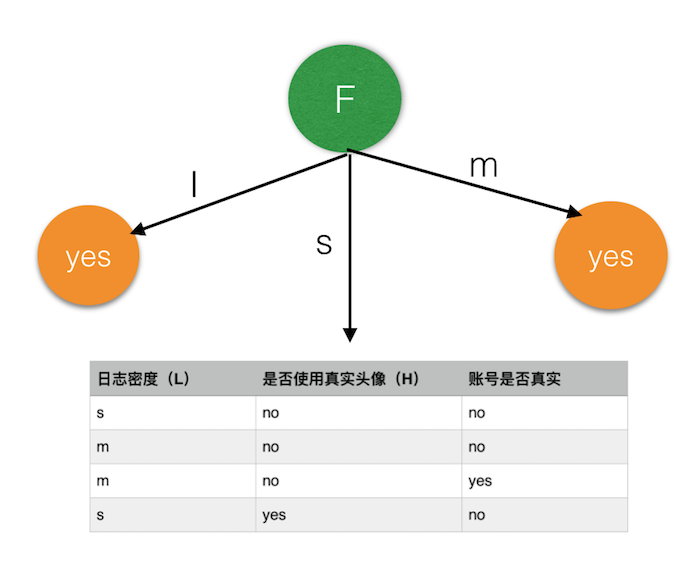
注意,F 属性有三个类别,对应三个分支,其中,l 和 m 两个分支的数据都是同一类(账号真实性要么都是 no 要么都是 yes),因此这两个分支没法再分了,而 s 属性的分支,剩下一个四个样本的子集,我们之后的任务,是对这个子集继续分割,直到没法再分为止。 接下来要考虑 L 和 H 属性,同样的道理,我们继续计算增益,只不过这一次我们是在这个子集上计算。
\[H(D)=-(\frac{3}{4}*log_2{\frac{3}{4}}+\frac{1}{4}*log_2{\frac{1}{4}})=0.811\]
\[Remainder(L)=\frac{1}{2}*(0)+\frac{1}{2}(-\frac{1}{2}log_2{\frac{1}{2}}-\frac{1}{2}log_2{\frac{1}{2}})=0.5\]
\[Remainder(H)=\frac{3}{4}*[-\frac{2}{3}log_2(\frac{2}{3})-\frac{1}{3}log_2(\frac{1}{3})]+\frac{1}{4}*0=0.689\]
\[Gain(L)=0.811-0.5=0.311\]
\[Gain(H)=0.811-0.689=0.122\]
这一次,我们选择 L 属性进行分裂:
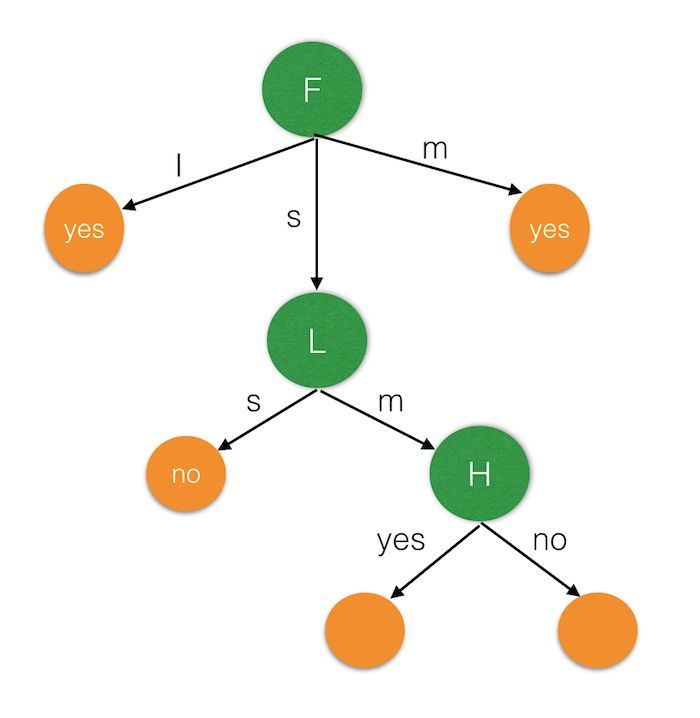
剩下的只有 H 属性,因此最后加上 H 节点。由于剩下的样本中只有 H=no 的数据,因此 yes 节点的数据没法判断(这种情况在数据量很大的时候一般不会遇到,因为数据量越大,涵盖的情况会更多),而剩下的两个样本存在 yes 和 no 两种情况,因此 no 节点往下也只能随机选择一种类别进行判断(这种情况一般是根据进行「多数表决」,即选择出现次数最多的类别作为最终类别,在数据量很大的情况下,出现次数一样多的情况几乎不会发生)。
属性为连续值的情况
上面给出的例子中,样本的特征都是离散值(e.g. s,m,l),而 ID3 算法确实也只对离散值起作用。如果遇到特征为连续值的情况,一般需要先将其离散化,例如:可以选定几个阈值\(a_1\),\(a_2\),\(a_3\)(\(a_1<a_2<a_3\)),根据这些阈值,将样本特征分为四类:\(f < a_1\),\(a_1 < f < a_2\),\(a_2 < f < a_3\),\(f > a_3\)。然后,便可以按照一般的思路构建决策树了。
C4.5算法
C4.5 算法主要对 ID3 进行了改进,用「增益率」来衡量属性的信息增益效率。算法中定义了「分裂信息」:
\(SplitInfo(A)=-\sum_{j=1}^{v}{\frac{|D_j|}{|D|}log_2{\frac{|D_j|}{|D|}}}\)
然后,通过该信息,定义增益率公式为:
\(GainRatio(A)=\frac{Gain(A)}{SplitInfo(A)}\)
C4.5选择具有最大「增益率」的属性作为分裂属性,而其余步骤,和 ID3 完全一致。
CART
CART 指的是分类回归树(Classification And Regression Tree)。顾名思义,这是一棵既可以用于分类,也可以用于回归的树。不同于上面的两种树,CART 每一个非叶子节点只有有两个分支,所以 CART 是一棵二叉树。下面我们按照分类和回归两个用途分别介绍 CART 的构建。
分类树的生成
CART 在选择分裂节点的时候,用「基尼指数(Gini)」来挑选最合适的特征进行分裂。所谓「基尼指数」,其实和 ID3 中熵的作用类似。假设我们有一个数据集 D,其中包含 N 个类别,那么「基尼指数」为: \[ Gini(D) = 1 - \sum_{j=1}^{N}{P_j^2} \] 其中,\(P_j\)表示每个类别出现的概率。 同熵一样,「基尼系数」的值越小,样本越纯,分类越容易。 我们根据 Gini 选择一个最合适的特征作为 CART 的分裂节点。注意,与 ID3 不同的是,如果特征的类别超过两类,CART 不会根据特征的所有类别分出子树,而是选择其中的一个类别,根据是否属于这个类别分成两棵子树。假设 A 特征中有三种类别(s、m、l),我们需要分别按照「是否属于 s 」、「是否属于 m 」、「是否属于 l 」将样本分为两类,根据 Gini 值最小的情况挑选出分裂的特征类别(比如:按照「是否属于 s 」将样本分为两类)。对于分裂后的样本的 Gini 值,我们按照如下公式计算: \[ Gini(D, A) = \sum_{j}^{k}{\frac{|D_j|}{|D|}} \] 其中,k 表示分裂的子集数目。事实上,在 CART 中,k 的取值为 2。 然后,选择 \(Gini(D, A)\) 最小的特征 A 作为分裂的特征即可。 这里还需要注意一点,在 ID3 中,已经选择过的特征是没法在之后的节点分裂中被选上的,即每个特征只能被挑选一次。但 CART 没有这种限制,每次都是将所有特征放在一起,通过「基尼系数」选出最好的,哪怕这个特征已经在之前被挑选过了。有学者认为,ID3 这种只挑选一次的做法容易导致 overfitting 问题,所以相信 CART 的这种做法能使模型的泛化能力更强。 CART 按照这样的方式,不断挑选特征分裂子数,直到剩下的子样本都属于同一类别,或者特征没法再分为止,这个停止条件可以参考 ID3 ,这里就不再举例说明了。
回归树的生成
回归树相对来说比较难理解,我自己也花了较长时间咀嚼,其中还有一些不明白的地方,日后有了新的想法会继续补充修正。 为了更好地说明回归树的构建流程,我们假设有以下训练数据:
| \(X\) | \(Y\) |
|---|---|
| (\(x_{11}\),\(x_{12}\),\(x_{13}\)) | \(y_1\) |
| (\(x_{21}\),\(x_{22}\),\(x_{23}\)) | \(y_2\) |
| (\(x_{31}\),\(x_{32}\),\(x_{33}\)) | \(y_3\) |
上面的表中一共有三个样本,每个样本有三个特征,为了解说方便,我们分别命名为特征 1、特征 2、特征 3(比如:\(x_{11}\),\(x_{21}\),\(x_{31}\) 就属于特征 1)。 与分类树类似,回归树每次也需要从样本 \(X\) 选取特征,并根据特征值将数据集切分为两份。在分类树中,我们是用「熵」或者「基尼系数」来确定分裂特征,但回归树中的 \(X\) 和 \(Y\) 都是连续值,因此需要采用新的特征挑选方式。 首先,我们先简单明确一下回归树的分裂原则:每次分裂后,每个样本集合内的数据要尽可能相似。这一点与分类树是不谋而合的,尽可能相似就是说,类别上要尽量统一。而为了做到这一点,最常用的方法便是「最小二乘法」。下面,我们定义「最小二乘法」的代价函数(可以简单认为就是回归树的信息熵): \[ \min_{j,s}[\min_{c_1}\sum_{x_i\ \in\ {R_1\ (j,s)}}{(y_i-c_1)}^2+\min_{c_2}\sum_{x_i\ \in\ {R_2\ (j,s)}}{(y_i-c_2)}^2] \]
其中,
- \(j\) 表示样本的特征,上面例子中的 \(x_{11}\),\(x_{21}\) 就属于同一个特征。
- \(s\) 表示特征的分裂值,如果 \(s=x_{11}\),就表示所有样本以特征 1 为基准,按照 \(>=x_{11}\) 和 \(<x_{11}\) 分为两类。
- \(R_1\) 表示分裂后的第一个样本集,\(R_2\) 表示分裂后的第二个样本集。
- \(c_1\)、\(c_2\) 分别表示 \(R_1\)、\(R_2\) 的固定输出值。简单点说,它们是最能代表 \(R_1\),\(R_2\) 内所有样本的值。
如果我们进一步对 \(\sum_{x_i\ \in\ {R_1\ (j,s)}}{(y_i-c_1)}^2\) 求导的话,就会发现,要使这个式子最小,\(c\) 必须取 \(y_i\) 的平均值( \(y_i \in R\) )。因此,我们对原公式进行简化: \[ \min_{j,s}[\sum_{x_i\ \in\ {R_1\ (j,s)}}{(y_i-c_1)}^2+\sum_{x_i\ \in\ {R_2\ (j,s)}}{(y_i-c_2)}^2] \] 其中,\(c_1\)、\(c_2\) 分别是 \(R_1\)、\(R_2\) 两个集合中 \(y\) 的平均值。
(希望上面对符号的说明能减少读者对公式的畏惧🤒)
这个公式的做法其实很简单,就是枚举所有特征以及特征值,挑选出最好的特征以及特征值作为分裂点,将样本分为两部分,其中,每一部分内的样本值 \(y\) 的平方差最小。平方差最小,意味着这个样本内的数据是最相近的,可以认为属于同一类。
至此,回归树的精髓部分就介绍完了。下面顺藤摸瓜讲一下回归树的构建过程。
最小二乘回归树生成算法:
- 依次遍历每个特征 j,根据所有样本中特征 j 的取值 s,我们按照上面的公式计算代价函数,这样便可以得到每对 ( \(j\),\(s\) ) 的代价函数,我们选择函数值最小的作为切分点;
- 使用上一步的切分点将数据分为两份;
- 重复第 1、2 步,直到样本的平方差小于阈值或样本数目小于阈值为止。此时,叶子节点的数据就是该样本空间 \(R_m\) 的平均值 \(c_m\);
- 根据第 3 步构造的各个样本空间 \(R_m\),生成回归树。
在本文参考的博文 CART之回归树构建内有一个构建回归树的简单例子,虽然计算方式略有不同,但和本文陈述的方法应该大同小异,我这里偷个懒,就不再举例了。