好久没更新了,一方面是因为工作繁忙,另一方面主要是懒。
之前写过几篇关于神经网络量化的文章,主要是对 Google 量化论文以及白皮书的解读,但有一些细节的问题当时没有提及。这篇文章想补充其中一个问题:关于 ElementwiseAdd (简称 EltwiseAdd) 和 Concat 的量化。
好久没更新了,一方面是因为工作繁忙,另一方面主要是懒。
之前写过几篇关于神经网络量化的文章,主要是对 Google 量化论文以及白皮书的解读,但有一些细节的问题当时没有提及。这篇文章想补充其中一个问题:关于 ElementwiseAdd (简称 EltwiseAdd) 和 Concat 的量化。
一个月前,女朋友让我做一个生成表情包的工具,趁着国庆的尾巴搞了一下,一番操作后,终于让懂王喜笑颜开了。

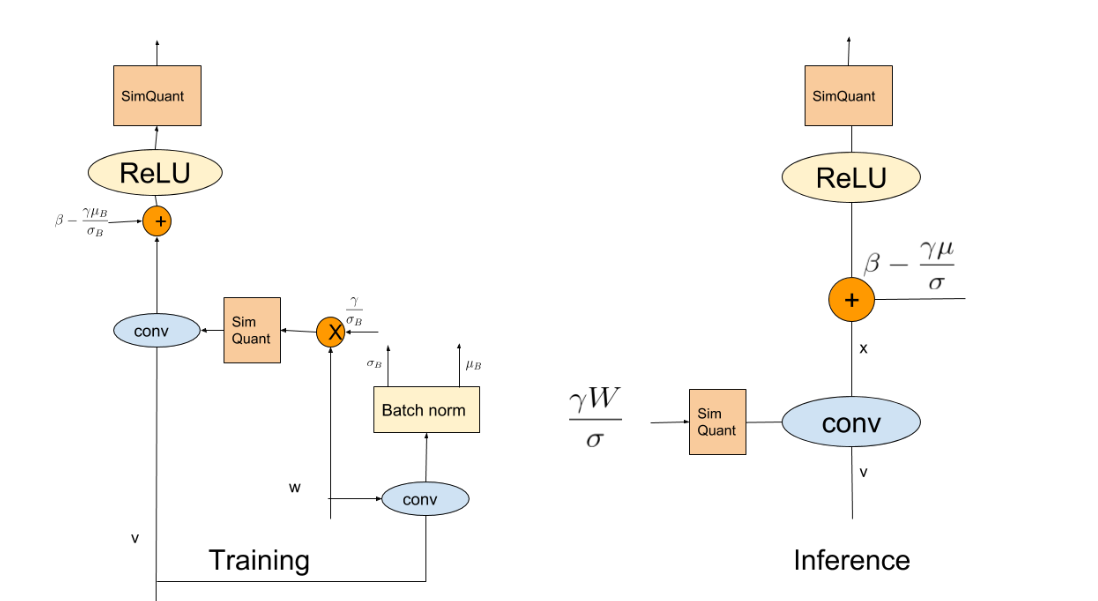
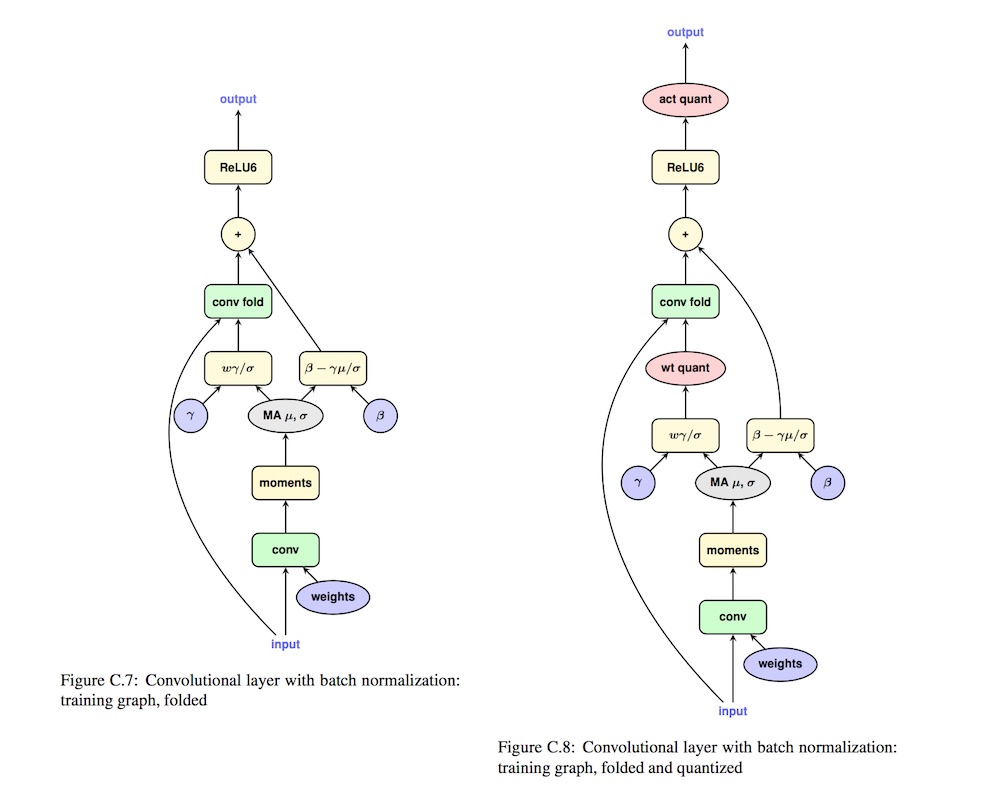
上一篇文章介绍了量化训练的基本流程,本文介绍量化中如何把 BatchNorm 和 ReLU 合并到 Conv 中。
上一篇文章介绍了后训练量化的基本流程,并用 pytorch 演示了最简单的后训练量化算法。
后训练量化虽然操作简单,并且大部分推理框架都提供了这类离线量化算法 (如 tensorrt、ncnn,SNPE 等),但有时候这种方法并不能保证足够的精度,因此本文介绍另一种比后训练量化更有效地量化方法——量化感知训练。
量化感知训练,顾名思义,就是在量化的过程中,对网络进行训练,从而让网络参数能更好地适应量化带来的信息损失。这种方式更加灵活,因此准确性普遍比后训练量化要高。当然,它的一大缺点是操作起来不方便,这一点后面会详谈。
同样地,这篇文章会讲解最简单的量化训练算法流程,并沿用之前文章的代码框架,用 pytorch 从零构建量化训练算法的流程。
上一篇文章介绍了矩阵量化的基本原理,并推广到卷积网络中。这一章开始,我会逐步深入到卷积网络的量化细节中,并用 pytorch 从零搭建一个量化模型,帮助读者实际感受量化的具体流程。
本章中,我们来具体学习最简单的量化方法——后训练量化「post training quantization」
由于本人接触量化不久,如表述有错,欢迎指正。
最近打算写一个关于神经网络量化的入门教程,包括网络量化的基本原理、离线量化、量化训练,以及全量化模型的推理过程,最后我会用 pytorch 从零构建一个量化模型,帮助读者形成更深刻的理解。
之所以要写这系列教程,主要是想帮助初次接触量化的同学快速入门。笔者在刚开始接触模型量化时走了很多弯路,并且发现网上的资料和论文对初学者来说太不友好。目前学术界的量化方法都过于花俏,能落地的极少,工业界广泛使用的还是 Google TFLite 那一套量化方法,而 TFLite 对应的大部分资料都只告诉你如何使用,能讲清楚原理的也非常少。这系列教程不会涉及学术上那些花俏的量化方法,主要是想介绍工业界用得最多的量化方案 (即 TFLite 的量化原理,对应 Google 的论文 Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference )
话不多说,我们开始。这一章中,主要介绍网络量化的基本原理,以及推理的时候如何跑量化模型。
这一个月来一直在研究计算机美学 (photo aesthetic) 的课题,因为有一个需求是帮助用户筛选出一些拍的比较好的图片。这段时间陆陆续续看了很多相关的文章,也一直在思考这个问题:让计算机来对图片进行审美,到底有没有可能?毕竟审美是一件很主观的事情,美的定义本身也不清晰,让需要明确指令的计算机来做一件人类都不明确的事情,这看起来就不太现实。
本文会记录一下我最近看过的一些文章,总结一下这个领域的研究思路,以及我个人的一些想法。
今天要聊聊用 PyTorch 进行 C++ 扩展。
在正式开始前,我们需要了解 PyTorch 如何自定义 module。这其中,最常见的就是在 python 中继承 torch.nn.Module,用 PyTorch 中已有的 operator 来组装成自己的模块。这种方式实现简单,但是,计算效率却未必最佳,另外,如果我们想实现的功能过于复杂,可能 PyTorch 中那些已有的函数也没法满足我们的要求。这时,用 C、C++、CUDA 来扩展 PyTorch 的模块就是最佳的选择了。
由于目前市面上大部分深度学习系统(TensorFlow、PyTorch 等)都是基于 C、C++ 构建的后端,因此这些系统基本都存在 C、C++ 的扩展接口。PyTorch 是基于 Torch 构建的,而 Torch 底层采用的是 C 语言,因此 PyTorch 天生就和 C 兼容,因此用 C 来扩展 PyTorch 并非难事。而随着 PyTorch1.0 的发布,官方已经开始考虑将 PyTorch 的底层代码用 caffe2 替换,因此他们也在逐步重构 ATen,后者是目前 PyTorch 使用的 C++ 扩展库。总的来说,C++ 是未来的趋势。至于 CUDA,这是几乎所有深度学习系统在构建之初就采用的工具,因此 CUDA 的扩展接口是标配。
本文用一个简单的例子,梳理一下进行 C++ 扩展的步骤,至于一些具体的实现,不做深入探讨。
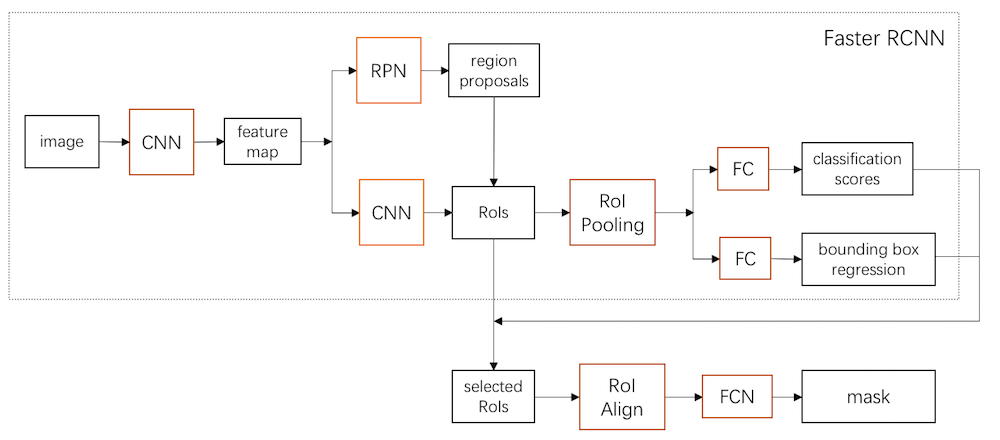
之前在一次组会上,师弟诉苦说他用 UNet 处理一个病灶分割的任务,但效果极差,我看了他的数据后发现,那些病灶区域比起整张图而言非常的小,而 UNet 采用的损失函数通常是逐像素的分类损失,如此一来,网络只要能够分割出大部分背景,那么 loss 的值就可以下降很多,自然无法精细地分割出那些细小的病灶。反过来想,这其实类似于正负样本极不均衡的情况,网络拟合了大部分负样本后,即使正样本拟合得较差,整体的 loss 也已经很低了。
发现这个问题后,我就在想可不可以先用 Faster RCNN 之类的先检测出这些病灶区域的候选框,再在框内做分割,甚至,能不能直接把 Faster RCNN 和分割部分做成一个统一的模型来处理。后来发现,这不就是 Mask RCNN 做的事情咩~囧~
这篇文章,我们就从无到有来看看 Mask RCNN 是怎么设计出来的。